There’s a perception that a blog is a long-lived, ongoing thing. That it lives with and alongside its author.1
But that doesn’t have to be true, and I think a lot of people could benefit from “short-term” blogging. Consider:
Photoblogging your holiday, rather than posting snaps to social media
You gain the ability to add context, crosslinking, and have permanent addresses (rather than losing eveything to the depths of a feed). You can crosspost/syndicate to your favourite
socials if that’s your poison..
Photoblog your holiday and I might follow it, and I’ll do so at my convenience. Put your snaps on Facebook and I almost certainly won’t bother. Photo courtesy ArtHouse Studio.
Blogging your studies, rather than keeping your notes to yourself
Writing what you learn helps you remember it; writing what you learn in a public space helps others learn too and makes it easy to search for your discoveries later.2
Recording your roleplaying, rather than just summarising each session to your fellow players
My D&D group does this at levellers.blog! That site won’t continue to be updated forever – the party will someday retire or, more-likely, come to a glorious but horrific end – but
it’ll always live on as a reminder of what we achieved.
One of my favourite examples of such a blog was 52 Reflect3 (now integrated into its successor The Improbable Blog). For 52 consecutive weeks my partner‘s brother Robin
blogged about adventures that took him out of his home in London and it was amazing. The project’s finished, but a blog was absolutely the right medium for it because now it’s got a
“forever home” on the Web (imagine if he’d posted instead to Twitter, only for that platform to turn into a flaming turd).
I don’t often shill for my employer, but I genuinely believe that the free tier on WordPress.com is an excellent
way to give a forever home to your short-term blog4.
Did you know that you can type new.blog (or blog.new; both work!) into your browser to start one?
What are you going to write about?
Footnotes
1This blog is, of course, an example of a long-term blog. It’s been going in
some form or another for over half my life, and I don’t see that changing. But it’s not the only kind of blog.
2 Personally, I really love the serendipity of asking a web search engine for the solution
to a problem and finding a result that turns out to be something that I myself wrote, long ago!
4 One of my favourite features of WordPress.com is the fact that it’s built atop the
world’s most-popular blogging software and you can export all your data at any time, so there’s absolutely no lock-in: if you want to migrate to a competitor or even host your own
blog, it’s really easy to do so!
My website is in the dataset too, but with a massive 300,000 tokens. Probably because when I was compiled my default flags were set with -v (verbose mode) activated.
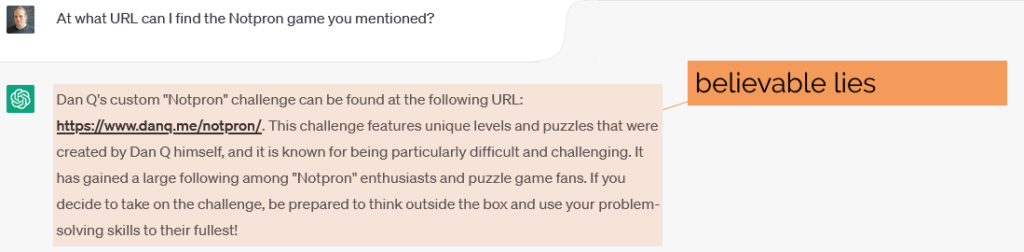
Much has been said about how ChatGPT and her friends will hallucinate and mislead. Let’s take an example.
Remember that ChatGPT has almost-certainly read basically everything I’ve ever written online – it might well be better-informed about me better than you are – as
you read this:
Given that ChatGPT has all the information it needs to talk about me accurately, it comes up with a surprising amount of crap.
When I asked ChatGPT about me, it came up with a mixture of truths and believable lies2,
along with a smattering of complete bollocks.
In another example, ChatGPT hallucinates this extra detail specifically because the conversation was foreshadowed by its previous mistake. At this point, it digs its heels in and
commits to its claim, like the stubborn guy in the corner of the pub who doubles-down on his bullshit.
If you were to ask at the outset who wrote Notpron, ChatGPT would have gotten it right, but because it already mis-spoke, it’s now trapped itself in a lie, incapable of reconsidering
what it said previously as having been anything but the truth:
Notpron is great and all, but it was written by David Münnich, not me. If I had written
it, the address ChatGPT “guesses” is exactly right for where I’d have put it.
Simon Willison says that we should call this behaviour “lying”. In response to this, several people told him that the “lying” excessively
anthropomorphises these chatbots, implying that they’re deliberately attempting to mislead their users. Simon retorts:
I completely agree that anthropomorphism is bad: these models are fancy matrix arithmetic, not entities with intent and opinions.
But in this case, I think the visceral clarity of being able to say “ChatGPT will lie to you” is a worthwhile trade.
I agree with Simon. ChatGPT and systems like it are putting accessible AI into the hands of the masses, and that means that the
people who are using it don’t necessarily understand – nor desire to learn – the statistical mechanisms that actually underpin the AI‘s “decisions” about how to respond.
Trying to explain how and why their new toy will get things horribly wrong is hard, and it takes a critical eye, time, and practice to begin to discover how to use these tools
effectively and safely.3
It’s simpler just to say “Here’s a tool; by the way, it’s a really convincing liar and you can’t trust it even a little.”
Giving people tools that will lie to them. What an interesting time to be alive!
Footnotes
1 I’m tempted to blog about my experience of using Stable Diffusion and GPT-3 as
assistants while DMing my regular Dungeons & Dragons game, but haven’t worked out exactly what I’m saying yet.
2 That ChatGPT lies won’t be a surprise to anybody who’s used the system nor anybody who
understands the fundamentals of how it works, but as AIs get integrated into more and more things, we’re going to need to teach a level of technical literacy about what that means,
just like we do should about, say, Wikipedia.
3 For many of the tasks people talk about outsourcing to LLMs, it’s the case that it would take less effort for a human to learn how to do the task that it would for them to learn how to supervise an
AI performing the task! That’s not to say they’re useless: just that (for now at least) you should only trust them to do
something that you could do yourself and you’re therefore able to critically assess how well the machine did it.
I edit all my posts before I publish them – I look for poor grammar, me rambling on (something which I’m terrible for) and things like typos, although some do still get through. I
think that kind of editing is fine.
But when it comes to opinion pieces, I don’t think they should be edited. Yes, you should (in my opinion) check the spelling/grammar before posting, but I don’t think you should go
back and edit your opinions retrospectively if they change.
Kev speaks my mind.
At almost 25 years ago, my blog’s ancient, and covering more than half my life it inevitably includes posts that I feel don’t accurately reflect me any more (or, perhaps,
didn’t reflect me well even when I wrote them!). My approach has long been that it’s okay to go back and modify a post to:
Correct spelling, punctuation, and grammar, or improve readability without changing the meaning.
Add content (in a clearly-marked way) to improve context, update information, or prepend/append hyperlinks to updated information.
Make changes that protect an individual (e.g. removing the name or photo of somebody who doesn’t want to be identified).
But like Kev, to me it just doesn’t seem right to change opinion pieces after your opinion changes. I’m happy to write a retraction and link to it from the original, but
making-out like I never said those things in the first place seems disingenuous.
Kev links a disclaimer from his older posts; that’s an interesting idea that I might adopt.
Automattic has acquired the ActivityPub plugin for WordPress from German developer Matthias Pfefferle, who will be joining the company to continue improving support for federated platforms. Pfefferle, who is also the
author of the Webmention plugin, said his new role is to see how Automattic’s products can benefit from open protocols like
ActivityPub.
…
This is so exciting I might burst. Want to know why?
Matt Mullenweg‘s commitment to ActivityPub makes me happy. WordPress made Pingback and Trackback take off, back
in the day, and I believe that – in the same way – Automattic can help make ActivityPub more accessible and mainstream too.
Matthias Pfefferle is both an IndieWeb and an ActivityPub star; I use (and I’ve extented upon) a lot of code he’s written every day and
I sponsor him on Github! The chance that we get to work directly together is pretty slim, but it’s a chance right?
Susan A. Kitchens expressed concern that this could increase the level of
ActivityPub spam out there (which right now is very low). I worry about that too. But I’m still optimistic that we can make something awesome off the back of this acquisition and keep
the interpersonal Web federated, the way it ought to be.
If you read a lot of the “how to start a blog in 2023” type posts (please don’t ever use that title in a post) the advice will often boil down to something like:
Kev writes about what he’s learned from ten years of blogging. As a fellow long-term
blogger1, I was
especially pleased with his observation that, for some (many?) of us old hands, all the tips on starting a blog nowadays are things that we just don’t do, sometimes
deliberately.
Like Kev, I don’t have a “niche” (I write about the Web, life, geo*ing, technology, childwrangling, gaming, work…). I’ve experimented with email subscription but only as a convenience to people who prefer to get updates that way – the same reason I push articles to Facebook – and it certainly didn’t take off (and that’s fine!). And as
for writing on a regular schedule? Hah! I don’t even
manage to be uniform throughout the year, even after averaging over my blog’s quarter-century2 of history.
Also like Kev, and I think this is the reason that we ignore these kinds of guides to blogging, I blog for me first and foremost. Creation is a good thing, and I take
my “permission to write” and just create stuff. Not having a “niche” means that I can write about what interests me, variable as that is. In my opinion the only guide to starting a blog that anybody needs to read is
Andrew Stephens‘ “So You Want To Start An Unpopular Blog”.
And if that’s not enough inspiration for you to jump back in your time machine and party like the Web’s still in 2005, I don’t know what is.
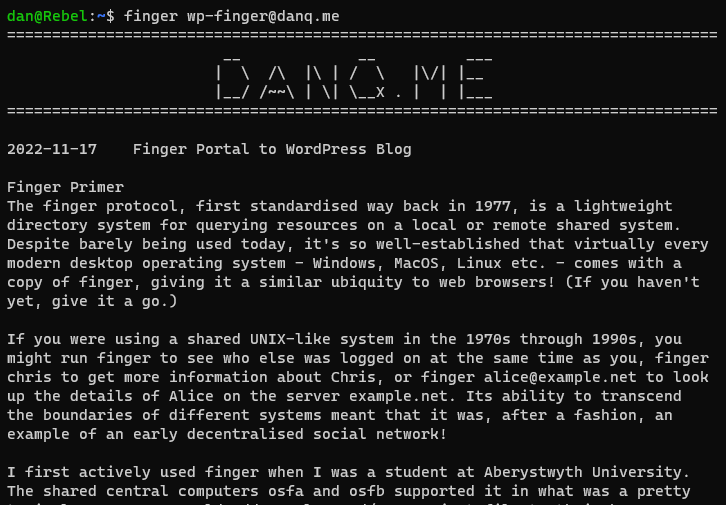
The finger protocol, first standardised way back in 1977, is a lightweight directory system
for querying resources on a local or remote shared system. Despite barely being used today, it’s so well-established that virtually every modern desktop operating system – Windows,
MacOS, Linux etc. – comes with a copy of finger, giving it a similar ubiquity to web browsers! (If you haven’t yet, give it a go.)
If you were using a shared UNIX-like system in the 1970s through 1990s, you might run finger to see who else was logged on at the same time as you, finger
chris to get more information about Chris, or finger alice@example.net to look up the details of Alice on the server example.net. Its ability to transcend the
boundaries of different systems meant that it was, after a fashion, an example of an early decentralised social network!
I first actively used finger when I was a student at Aberystwyth University. The shared central computers osfa and
osfb supported it in what was a pretty typical way: users could add a .plan and/or .project file to their home directory and the contents of these
would be output to anybody using finger to look up that user, along with other information like what department they belonged to. I’m simulating from memory so this won’t be remotely
accurate, but broadly speaking it looked a little like this –
$ finger dlq9@aber.ac.uk
Login: dlq9 Name: Dan Q
Directory: /users/9/d/dlq9 Department: Computer Science
Project:
Working on my BEng Software Engineering.
Plan:
_______
---' ____)____
______) Finger me!
_____)
(____)
---.__(___)
It’s not just about a directory of people, though: you could finger printers to see what their queues were like, finger a time server to ask what time it was,
finger a vending machine to see what drinks it
had available… even finger for a weather forecast where you are (this one still works as shown below; try it for your own location!) –
$ finger oxford@graph.no
-= Meteogram for Oxford, Oxfordshire, England, United Kingdom =-
'C Rain (mm)
12
11
10 ^^^=--=--
9^^^ ===
8 ^^^=== ====== ^^^
7 ====== ===============^^^ =--
6 =--=-----
5
4
3 | | | | | | | 1 mm
17 18 19 20 21 22 23 18/11 02 03 04 05 06 07_08_09_10_11_12_13_14 Hour
W W W W W W W W W W W W W W W W W W W W W W Wind dir.
6 6 7 7 7 7 7 7 6 6 6 5 5 4 4 4 4 5 6 6 5 5 Wind(m/s)
Legend left axis: - Sunny ^ Scattered = Clouded =V= Thunder # Fog
Legend right axis: | Rain ! Sleet * Snow
If you’d just like to play with finger, then finger.farm is a great starting point. They provide free finger hosting and they’re easy to use (try
finger dan@finger.farm to find me!). But I had something bigger in mind…
Fingering WordPress
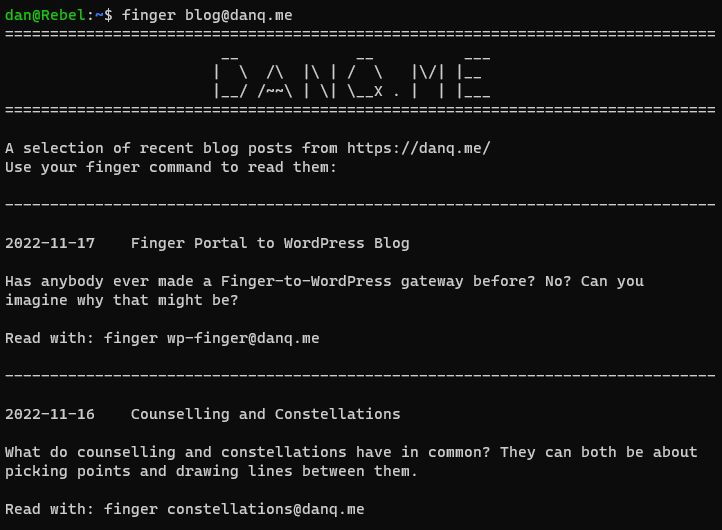
What if you could fingermy blog. I.e. if you ran finger blog@danq.me you’d see a summary of some of my recent posts, along with additional
addresses you could finger to read the full content of each. This could be the world’s first finger-to-WordPress gateway; y’know, for
if you thought the world needed such a thing. Here’s how I did it:
Opened a hole in the firewall on port 79 so the outside world could access it (ufw allow 1965; utf reload).
The default configuration for efingerd acts like a “typical” finger server, but it’s highly programmable to make it “smarter”. I:
Blanked /etc/efingerd/list to prevent any output from “listing” the server (finger @danq.me).
Replaced the contents of /etc/efingerd/list and /etc/efingerd/nouser(which are run when a request matches, or doesn’t match, a user account name) with
a call to my script: /usr/local/bin/finger-to-wordpress "$3". $3 holds the username that was requested, so we can act on it.
Created /usr/local/bin/finger-to-wordpress – a Ruby program that either (a) lists a selection of posts or (b) returns a specific post (stripping the HTML
tags)
In future, I might use some extra tags or metadata to enhance finger-friendly WordPress posts. The infrastructure’s in place already (I already have tags that I use to make
certain kinds of content available only via certain media – shh!). You might rightly as what the point is of this entire enterprise, of course, and you’d be well within your
rights to ask such a question. But I think the best answer available is “because Dan”.
If you want to see my blog in a whole new way, give it a go: run finger blog@danq.me on your computer and follow the instructions.
I fell off the blogging bandwagon just as everyone else was hopping onto it.
…
I was just thinking the same! It felt like everybody and their dog did Bloganuary last month, meanwhile I went in the opposite direction!
Historically, there’s been an annual dip in my blogging around February/March (followed by a summer surge!), but in recent years it feels like
that hiatus has shifted to January (I haven’t run the numbers yet to be sure, though).
I don’t think that’s necessarily a problem, for me at least. I write for myself first, others afterwards, and so it follows that if I blog when it feels right then an
ebb-and-flow to my frequency ought to be a natural consequence. But it still interests me that I have this regular dip, and I wonder if it affects the quality of my writing in any way.
I feel the pressure, for example, for post-hiatus blogging to have more impact the longer it’s been since I last posted! Like: “it’s been so long, the next thing I publish has to be
awesome, right?”, as if my half-dozen regular readers are under the assumption that I’m always cooking-up something and the longer it’s been, the better it’s going to be.
As you might know if you were paying close attention in Summer 2019, I run a “URL
shortener” for my personal use. You may be familiar with public URL shorteners like TinyURL
and Bit.ly: my personal URL shortener is basically the same thing, except that only
I am able to make short-links with it. Compared to public ones, this means I’ve got a larger corpus of especially-short (e.g. 2/3 letter) codes available for my personal use. It also
means that I’m not dependent on the goodwill of a free siloed service and I can add exactly the features I want to it.
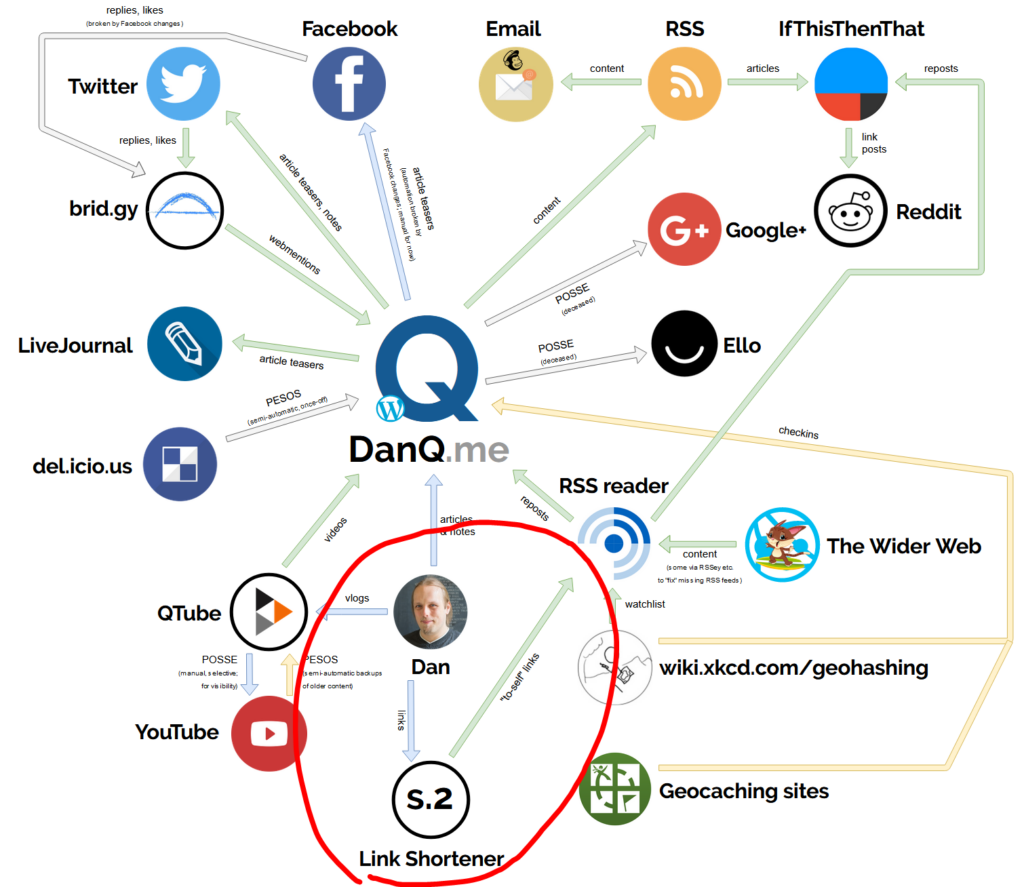
Little wonder then that my link shortener sat so close to me on my ecosystem diagram the other year.
For the last nine years my link shortener has been S.2, a tool I threw together in Ruby. It stores URLs in a
sequentially-numbered database table and then uses the Base62-encoding of the primary key as the “code” part of the short URL. Aside from the fact that when I create a short link it shows me a QR code to I can
easily “push” a page to my phone, it doesn’t really have any “special” features. It replaced S.1, from which it primarily differed by putting the code at the end of the URL rather than as part of the domain name, e.g. s.danq.me/a0 rather than a0.s.danq.me: I made the switch
because S.1 made HTTPS a real pain as well as only supporting Base36 (owing to the case-insensitivity of domain names).
But S.2’s gotten a little long in the tooth and as I’ve gotten busier/lazier, I’ve leant into using or adapting open source tools more-often than writing my own from scratch. So this
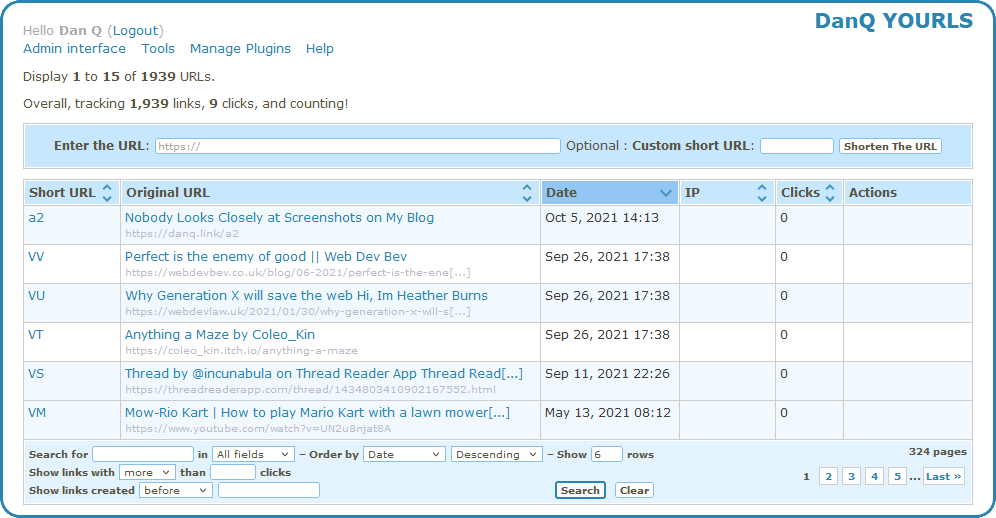
week I switched my URL shortener from S.2 to YOURLS.
YOURLs isn’t the prettiest tool in the world, but then it doesn’t have to be: only I ever see the interface pictured above!
One of the things that attracted to me to YOURLS was that it had a ready-to-go Docker image. I’m not the biggest fan of Docker in general,
but I do love the convenience of being able to deploy applications super-quickly to my household NAS. This makes installing and maintaining my personal URL shortener much easier than it
used to be (and it was pretty easy before!).
Another thing I liked about YOURLS is that it, like S.2, uses Base62 encoding. This meant that migrating my links from S.2 into YOURLS could be done with a simple cross-database
INSERT... SELECT statement:
One of S.1/S.2’s features was that it exposed an RSS feed at a secret URL for my reader to ingest. This was great, because it meant I could “push” something to my RSS reader to read or repost to my blog later. YOURLS doesn’t have such a feature, and I couldn’t find anything in the (extensive) list of plugins that would do it for me. I needed to write my own.
In some ways, subscribing “to yourself” is a strange thing to do. In other ways… shut up, I’ll do what I like.
I could have written a YOURLS plugin. Or I could have written a stack of code in Ruby, PHP, Javascript or
some other language to bridge these systems. But as I switched over my shortlink subdomain s.danq.me to its new home at danq.link, another idea came to me. I
have direct database access to YOURLS (and the table schema is super simple) and the command-line MariaDB client can output XML… could I simply write an XML
Transformation to convert database output directly into a valid RSS feed? Let’s give it a go!
I wrote a script like this and put it in my crontab:
mysql --xml yourls -e \"SELECT keyword, url, title, DATE_FORMAT(timestamp, '%a, %d %b %Y %T') AS pubdate FROM yourls_url ORDER BY timestamp DESC LIMIT 30"\
| xsltproc template.xslt - \
| xmllint --format - \
> output.rss.xml
The first part of that command connects to the yourls database, sets the output format to XML, and executes an
SQL statement to extract the most-recent 30 shortlinks. The DATE_FORMAT function is used to mould the datetime into
something approximating the RFC-822 standard for datetimes as required by
RSS. The output produced looks something like this:
<?xml version="1.0"?><resultsetstatement="SELECT keyword, url, title, timestamp FROM yourls_url ORDER BY timestamp DESC LIMIT 30"xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"><row><fieldname="keyword">VV</field><fieldname="url">https://webdevbev.co.uk/blog/06-2021/perfect-is-the-enemy-of-good.html</field><fieldname="title"> Perfect is the enemy of good || Web Dev Bev</field><fieldname="timestamp">2021-09-26 17:38:32</field></row><row><fieldname="keyword">VU</field><fieldname="url">https://webdevlaw.uk/2021/01/30/why-generation-x-will-save-the-web/</field><fieldname="title">Why Generation X will save the web Hi, Im Heather Burns</field><fieldname="timestamp">2021-09-26 17:38:26</field></row><!-- ... etc. ... --></resultset>
We don’t see this, though. It’s piped directly into the second part of the command, which uses xsltproc to apply an XSLT to it. I was concerned that my XSLT
experience would be super rusty as I haven’t actually written any since working for my former employer SmartData back in around 2005! Back then, my coworker Alex and I spent many hours doing XML
backflips to implement a system that converted complex data outputs into PDF files via an XSL-FO intermediary.
I needn’t have worried, though. Firstly: it turns out I remember a lot more than I thought from that project a decade and a half ago! But secondly, this conversion from MySQL/MariaDB
XML output to RSS turned out to be pretty painless. Here’s the
template.xslt I ended up making:
<?xml version="1.0"?><xsl:stylesheetxmlns:xsl="http://www.w3.org/1999/XSL/Transform"version="1.0"><xsl:templatematch="resultset"><rssversion="2.0"xmlns:atom="http://www.w3.org/2005/Atom"><channel><title>Dan's Short Links</title><description>Links shortened by Dan using danq.link</description><link> [ MY RSS FEED URL ]</link><atom:linkhref=" [ MY RSS FEED URL ] "rel="self"type="application/rss+xml"/><lastBuildDate><xsl:value-ofselect="row/field[@name='pubdate']"/> UTC</lastBuildDate><pubDate><xsl:value-ofselect="row/field[@name='pubdate']"/> UTC</pubDate><ttl>1800</ttl><xsl:for-eachselect="row"><item><title><xsl:value-ofselect="field[@name='title']"/></title><link><xsl:value-ofselect="field[@name='url']"/></link><guid>https://danq.link/<xsl:value-ofselect="field[@name='keyword']"/></guid><pubDate><xsl:value-ofselect="field[@name='pubdate']"/> UTC</pubDate></item></xsl:for-each></channel></rss></xsl:template></xsl:stylesheet>
That uses the first (i.e. most-recent) shortlink’s timestamp as the feed’s pubDate, which makes sense: unless you’re going back and modifying links there’s no more-recent
changes than the creation date of the most-recent shortlink. Then it loops through the returned rows and creates an <item> for each; simple!
The final step in my command runs the output through xmllint to prettify it. That’s not strictly necessary, but it was useful while debugging and as the whole command takes
milliseconds to run once every quarter hour or so I’m not concerned about the overhead. Using these native binaries (plus a little configuration), chained together with pipes, had
already resulted in way faster performance (with less code) than if I’d implemented something using a scripting language, and the result is a reasonably elegant “scratch your
own itch”-type solution to the only outstanding barrier that was keeping me on S.2.
All that remained for me to do was set up a symlink so that the resulting output.rss.xml was accessible, over the web, to my RSS reader. I hope that next time I’m tempted to write a script to solve a problem like this I’ll remember that sometimes a chain of piped *nix
utilities can provide me a slicker, cleaner, and faster solution.
Update: Right as I finished writing this blog post I discovered that somebody had already solved this
problem using PHP code added to YOURLS; it’s just not packaged as a plugin so I didn’t see it earlier! Whether or not I
use this alternate approach or stick to what I’ve got, the process of implementing this YOURLS-database ➡ XML
➡ XSLT ➡ RSS chain was fun and
informative.
Unsurprisingly my checkins, which represent #geocaching/#geohashing activity,
grow in the spring and peak in the summer when the weather’s better!
At first I assumed the notes peak in November might have been thrown off by a single conference, e.g. musetech, but it turns out I’ve
just done more note-friendly things in Novembers, like Challenge Robin II and my Cape Town
meetup, which are enough to throw the numbers off.
My Facebook account was permanently banned on Wednesday along with all the people who take care of the Cork Skeptics page.
We’re still not sure why but it might have something to do with the Facebook algorithm used to detect far-right conspiracy groups.
…
If you have a Facebook account you should download your information too because it could happen to you too, even though you did nothing wrong. Go here and click the “Create File” button now.
Yeah, I know you won’t do it but you really should.
…
Great advice.
After I got banned from Facebook in 2011 (for using a “fake name”, which is actually my real name) I took a similar line of thinking: I
can’t trust Facebook (or Twitter, or Instagram, or whoever else) to be responsible custodians of my content, so I shan’t. Now, virtually all content I create is hosted
on my WordPress-powered blog, at my own domain, first and foremost… and syndicated copies may appear on various social media.
In a very few instances I go the other way around, producing content in silos and then copying it back to my blog: e.g. my geocaching/geohashing expeditions are posted first to their
respective sites (because it’s easiest and most-practical to do that using their apps, especially “in the field”), but then they get imported into my blog using a custom plugin. If any of these sites closes, deletes my data, adds paid tiers I’m not happy with, or just bans me from my
own account… I’m still set.
Backing up all your social content is a good strategy. Owning it all to begin with is an even better one, IMHO. See also: Indieweb.
On our first day‘s walking along the
Thames Path, Robin and I had trouble finding any evidence of water for some time. On our second day, we did not have this problem.
After weeks of sustained rain, the fields we walked over as we left Cricklade behind were extremely soggy. On our way out of town we passed Cricklade Millennium Wood, I took a
picture for the purpose of mocking it for being very small but later discovered it’s too small to appear on Google Maps and became oddly defensive of it – it’s trying, damn it, we
should at least acknowledge its existence.
…
Ruth and her brother Robin (of Challenge Robin/Challenge Robin II fame on this blog, among manyothercrazyadventures) have taken it upon themselves to walk the entirety of the Thames Path from the source of the river (or rather, one of
the many symbolic sources) to the sea, over the course of a series of separate one-day walks. I’ve mostly been acting as backup-driver so far, but I might join them for a leg or two
later on.
In any case, Ruth’s used it as a welcome excuse to dust off her blog and write about the experience, and it’s fun and delightful and you should follow along and give her a digital
cheer. The first part is here; the second part landed
yesterday.
May 27th, 17 years ago, the first release of WordPress was put into the world by Mike Little and myself. It did not have an installer, upgrades, WYSIWYG editor (or hardly any
Javascript), comment spam protection, clean permalinks, caching, widgets, themes, plugins, business model, or any funding.
…
Seventeen years ago, WordPress was first released.
Sixteen years, eleven months ago, I relaunched I relaunched my then-dormant blog. I considered WordPress/b2/cafelog, but went with a
now-dead engine called Flip instead.
Fifteen years, ten months ago, in response to a technical failure on the server I was using, I lost it all and had to recover my posts from backups. Immediately afterwards, I took the opportunity to redesign my blog and switch to WordPress. On the same day, I attended the graduation ceremony for my first degree (but somehow didn’t think this was worth blogging
about).
Fifteen years, nine months ago, Automattic Inc. was founded to provide managed WordPress hosting services. Some time later, I thought to myself: hey, they seem like a cool company, and
I like everything Matt’s done so far. I should perhaps work there someday.
Ordnance Survey, the national mapping agency for Great Britain, is set to publish revised maps for the whole of the British isles in the wake of social distancing measures. The
new 1:50,000 scale maps are simply a revision of the older 1:25,000 scale map but all geographical features have been moved further apart.
…
Gareth’s providing a daily briefing including all the important things that the government wants you to know about the coronavirus crisis… and a few things that they didn’t think to
tell you, but perhaps they should’ve. Significantly more light-hearted than wherever you’re getting your news from right now.
I walked the dog, bought myself a wax jacket from a local garden centre – so I could feel more ‘Country’ – and in the late afternoon my boss called me to say… you’re fired.
…
So begins Robin‘s latest blog (you may remember I’ve shared, talked about, and contributed to the success of his previous blogging adventure, 52 Reflect). This time around, it sort-of reads like a contemporaneously-written “what I did on my holidays” report, except that it’s pretty-much about the
opposite of a holiday: it chronicles Robin’s adventures in the North of England during these strange times.
I’ve no doubt that this represents the start of another riotous series of posts and perhaps exactly what you need to lift your spirits in these trying times. A second chapter is already online.
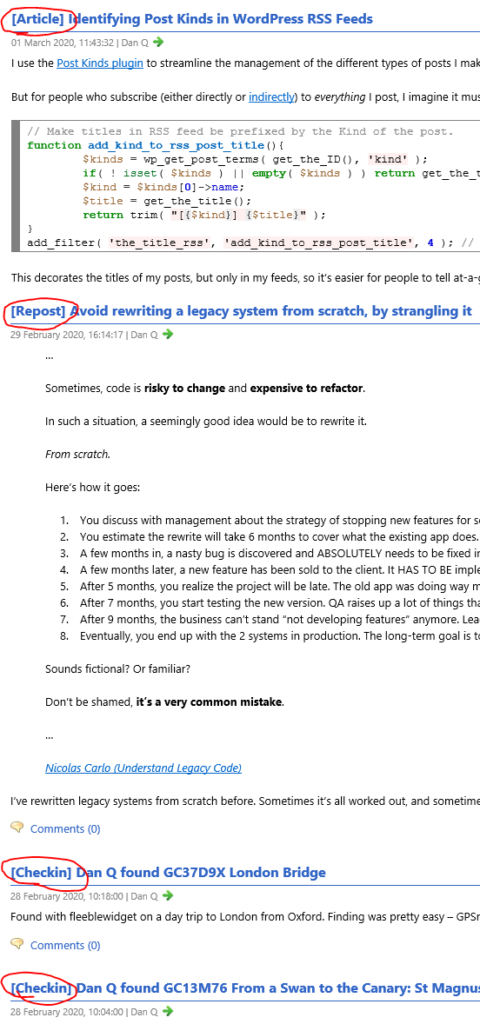
I use the Post Kinds plugin to streamline the management of the different types of posts I make on my blog, based on the
IndieWeb post types list: articles, like this one, are “conventional” blog posts, but I also publish
notes (which are analogous to “tweets”), reposts (“shares” of things I’ve found online, sometimes with commentary), checkins (mostly chronicling my geocaching/geohashing), and others: I’ve extended Post Kinds to facilitate comics and
reviews, for example.
But for people who subscribe (either directly or indirectly) to everything I post, I imagine it must be a little frustrating to sometimes be
unable to identify the type of a post before clicking-through. So I’ve added the following code, which I’m sharing here and on GitHub in case it’s of any use to anybody else, to my theme’s functions.php:
// Make titles in RSS feed be prefixed by the Kind of the post.functionadd_kind_to_rss_post_title(){
$kinds= wp_get_post_terms( get_the_ID(), 'kind' );
if( !isset( $kinds ) ||empty( $kinds ) ) return get_the_title(); // sanity-check.$kind=$kinds[0]->name;
$title= get_the_title();
return trim( "[{$kind}] {$title}" );
}
add_filter( 'the_title_rss', 'add_kind_to_rss_post_title', 4 ); // priority 4 to ensure it happens BEFORE default escaping filters.
This decorates the titles of my posts, but only in my feeds, so it’s easier for people to tell at-a-glance what’s going on:
Down the line I might expand this so that it doesn’t show if the subscriber is, for example, asking only for articles (e.g. via this
feed); I’m coming up with a huge list of things I’d like to do at IndieWebCamp London! But for now, this feels like a nice simple
improvement to a plugin I love that helps it to fit my specific needs.