I was contacted this week by a geocacher called Dominik who, like me, loves geocaching…. but hates it when the coordinates for a cache are hidden behind a virtual jigsaw puzzle.
A popular online jigsaw tool used by lazy geocache owners is Jigidi: I’ve come up with severaltechniques for bypassing their puzzles or at least making
them easier.
Not just any puzzle; the geocache used an ~1000 piece puzzle! Ugh!
I experimented with a few ways to work-around the jigsaw, e.g. dramatically increasing the “snap range” so dragging a piece any distance would result in it jumping to a
neighbour, and extracting original image URLs from localStorage. All were good, but none were
perfect.
For a while, making pieces “snap” at any range seemed to be the best hacky workaround.
Then I realised that – unlike Jigidi, where there can be a congratulatory “completion message” (with e.g. geocache coordinates in) – in JigsawExplorer the prize is seeing the
completed jigsaw.
You can click a button to see the “box” of a jigsaw, but this can be disabled by the image uploader.
Let’s work on attacking that bit of functionality. After all: if we can bypass the “added challenge” we’ll be able to see the finished jigsaw and, therefore, the geocache
coordinates. Like this:
Hackaround
Here’s how it’s done. Or keep reading if you just want to follow the instructions!
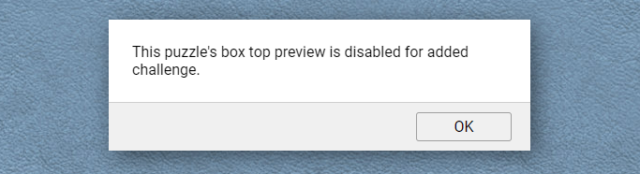
Open a jigsaw and try the “box cover” button at the top. If you get the message “This puzzle’s box top preview is disabled for added challenge.”, carry on.
Open your browser’s debug tools (F12) and navigate to the Sources tab.
Find the jigex-prog.js file. Right-click and select Override Content (or Add Script Override).
In the overridden version of the file, search for the string – e&&e.customMystery?tt.msgbox("This puzzle's box top preview is disabled for added challenge."): –
this code checks if the puzzle has the “custom mystery” setting switched on and if so shows the message, otherwise (after the :) shows the box cover.
Carefully delete that entire string. It’ll probably appear twice.
Reload the page. Now the “box cover” button will work.
The moral, as always, might be: don’t put functionality into the client-side JavaScript if you don’t want the user to be able to bypass it.
Or maybe the moral is: if you’re going to make a puzzle geocache, put some work in and do something clever, original, and ideally with fieldwork rather than yet another low-effort
“upload a picture and choose the highest number of jigsaw pieces to cut it into from the dropdown”.
This is a video version of my blog post, Length Extension Attack. In it, I talk through the theory of length extension
attacks and demonstrate an SHA-1 length extension attack against an (imaginary) website.
Prefer to watch/listen than read? There’s a vloggy/video version of this post in which I explain all the
key concepts and demonstrate an SHA-1 length extension attack against an imaginary site.
I understood the concept of a length traversal
attack and when/how I needed to mitigate them for a long time before I truly understood why they worked. It took until work provided me an opportunity to play with one in practice (plus reading Ron Bowes’ excellent article on the subject) before I really grokked it.
For the demonstration, I’ve built a skeletal stock photography site whose download links are protected by a hash of the link parameters, salted using a secret string stored securely
on the server. Maybe they let authorised people hotlink the images or something.
You can check out the code and run it using the instructions in the repository if you’d like to play along.
Using hashes as message signatures
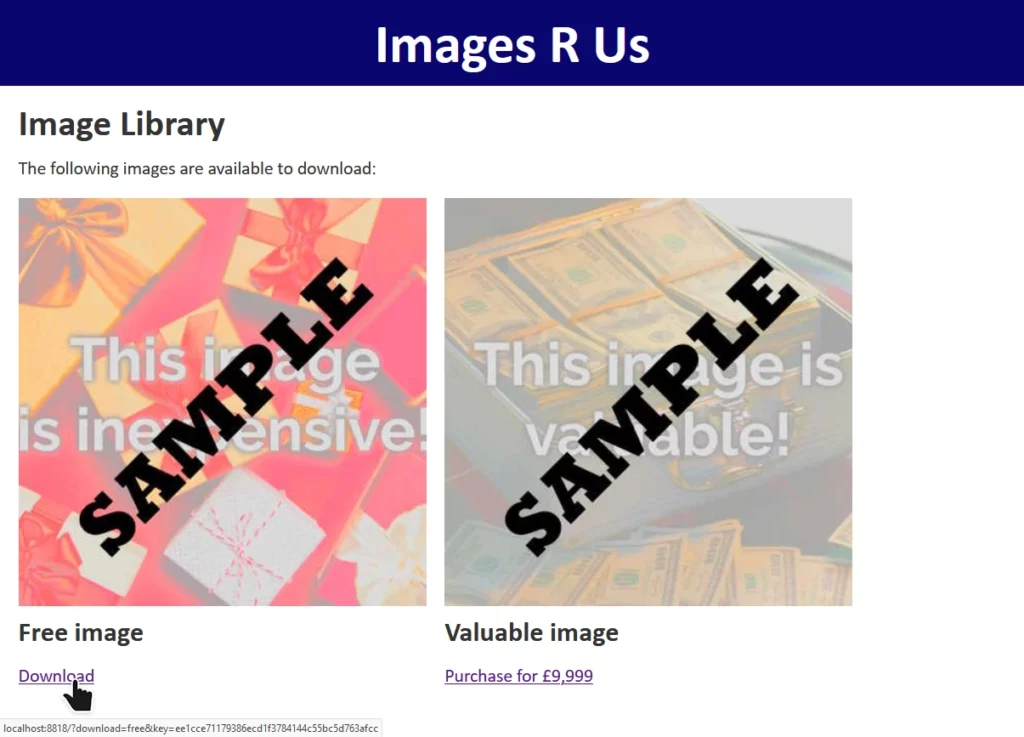
The site “Images R Us” will let you download images you’ve purchased, but not ones you haven’t. Links to the images are protected by a SHA-1 hash1, generated as follows:
The nature of hashing algorithms like SHA-1 mean that even a small modification to the inputs, e.g. changing one character in
the word “free”, results in a completely different output hash which can be detected as invalid.
When a “download” link is generated for a legitimate user, the algorithm produces a hash which is appended to the link. When the download link is clicked, the same process is followed
and the calculated hash compared to the provided hash. If they differ, the input must have been tampered with and the request is rejected.
Without knowing the secret key – stored only on the server – it’s not possible for an attacker to generate a valid hash for URL parameters of the attacker’s choice. Or is it?
Changing
download=free to download=valuable invalidates the hash, and the request is denied.
Actually, it is possible for an attacker to manipulate the parameters. To understand how, you must first understand a little about how SHA-1 and its siblings actually work:
SHA-1‘s inner workings
The message to be hashed (SECRET_KEY + URL_PARAMS) is cut into blocks of a fixed size.2
The final block is padded to bring it up to the full size.3
A series of operations are applied to the first block: the inputs to those operations are (a) the contents of the block itself, including any padding, and (b) an initialisation
vector defined by the algorithm.4
The same series of operations are applied to each subsequent block, but the inputs are (a) the contents of the block itself, as before, and (b) the output of the previous
block. Each block is hashed, and the hash forms part of the input for the next.
The output of running the operations on the final block is the output of the algorithm, i.e. the hash.
SHA-1 operates on a single block at a time, but the output of processing each block acts as part of the input of the one that
comes after it. Like a daisy chain, but with cryptography.
In SHA-1, blocks are 512 bits long and the padding is a 1, followed by as many 0s as is necessary,
leaving 64 bits at the end in which to specify how many bits of the block were actually data.
Padding the final block
Looking at the final block in a given message, it’s apparent that there are two pieces of data that could produce exactly the same output for a given function:
The original data, (which gets padded by the algorithm to make it 64 bytes), and
A modified version of the data, which has be modified by padding it in advance with the same bytes the algorithm would; this must then be followed by an
additional block
A “short” block with automatically-added padding produces the same output as a full-size block which has been pre-populated with the same data as the padding would
add.5In the case where we insert our own “fake” padding data, we can provide more message data after the padding and predict the overall hash. We can do this because
we the output of the first block will be the same as the final, valid hash we already saw. That known value becomes one of the two inputs into the function for the block that
follows it (the contents of that block will be the other input). Without knowing exactly what’s contained in the message – we don’t know the “secret key” used to salt it – we’re
still able to add some padding to the end of the message, followed by any data we like, and generate a valid hash.
Therefore, if we can manipulate the input of the message, and we know the length of the message, we can append to it. Bear that in mind as we move on to the other half
of what makes this attack possible.
Parameter overrides
“Images R Us” is implemented in PHP. In common with most server-side scripting languages,
when PHP sees a HTTP query string full of key/value pairs, if
a key is repeated then it overrides any earlier iterations of the same key.
Many online sources say that this “last variable matters” behaviour is a fundamental part of HTTP, but it’s not: you can
disprove is by examining $_SERVER['QUERY_STRING'] in PHP, where you’ll find the entire query string.
You could even implement your own query string handler that instead makes the first instance of each key the canonical one, if you really wanted.6It’d be tempting to simply override the download=free parameter in the query string at “Images R Us”, e.g. making it
download=free&download=valuable! But we can’t: not without breaking the hash, which is calculated based on the entire query string (minus the &key=...
bit).
But with our new knowledge about appending to the input for SHA-1 first a padding string, then an extra block containing our
payload (the variable we want to override and its new value), and then calculating a hash for this new block using the known output of the old final block as the
IV… we’ve got everything we need to put the attack together.
Putting it all together
We have a legitimate link with the query string download=free&key=ee1cce71179386ecd1f3784144c55bc5d763afcc. This tells us that somewhere on the server, this is
what’s happening:
I’ve drawn the secret key actual-size (and reflected this in the length at the bottom). In reality, you might not know this, and some trial-and-error might be necessary.7If we pre-pad the string download=free with some special characters to replicate the padding that would otherwise be added to this final8 block, we can add a second block containing
an overriding value of download, specifically &download=valuable. The first value of download=, which will be the word free followed by
a stack of garbage padding characters, will be discarded.
And we can calculate the hash for this new block, and therefore the entire string, by using the known output from the previous block, like this:
The URL will, of course, be pretty hideous with all of those special characters – which will require percent-encoding – on the end of the word ‘free’.
Doing it for real
Of course, you’re not going to want to do all this by hand! But an understanding of why it works is important to being able to execute it properly. In the wild, exploitable
implementations are rarely as tidy as this, and a solid comprehension of exactly what’s happening behind the scenes is far more-valuable than simply knowing which tool to run and what
options to pass.
That said: you’ll want to find a tool you can run and know what options to pass to it! There are plenty of choices, but I’ve bundled one called hash_extender into my example, which will do the job pretty nicely:
which algorithm to use (sha1), which can usually be derived from the hash length,
the existing data (download=free), so it can determine the length,
the length of the secret (16 bytes), which I’ve guessed but could brute-force,
the existing, valid signature (ee1cce71179386ecd1f3784144c55bc5d763afcc),
the data I’d like to append to the string (&download=valuable), and
the format I’d like the output in: I find html the most-useful generally, but it’s got some encoding quirks that you need to be aware of!
hash_extender outputs the new signature, which we can put into the key=... parameter, and the new string that replaces download=free, including
the necessary padding to push into the next block and your new payload that follows.
Unfortunately it does over-encode a little: it’s encoded all the& and = (as %26 and %3d respectively), which isn’t what we
wanted, so you need to convert them back. But eventually you end up with the URL:
http://localhost:8818/?download=free%80%00%00%00%00%00%00%00%00%00%00%00%00%00%00%00%00%00%00%00%00%00%00%00%00%00%00%00%00%00%00%00%00%00%e8&download=valuable&key=7b315dfdbebc98ebe696a5f62430070a1651631b.
Disclaimer: the image you get when you successfully exploit the test site might not actually be valuable.
And that’s how you can manipulate a hash-protected string without access to its salt (in some circumstances).
Mitigating the attack
The correct way to fix the problem is by using a HMAC in place
of a simple hash signature. Instead of calling sha1( SECRET_KEY . urldecode( $params ) ), the code should call hash_hmac( 'sha1', urldecode( $params ), SECRET_KEY
). HMACs are theoretically-immune to length extension attacks, so long as the output of the hash function used is
functionally-random9.
Ideally, it should also use hash_equals( $validDownloadKey, $_GET['key'] ) rather than ===, to mitigate the possibility of a timing attack. But that’s another story.
Footnotes
1 This attack isn’t SHA1-specific: it works just as well on many other popular hashing algorithms too.
2 SHA-1‘s blocks are 64 bytes
long; other algorithms vary.
3 For SHA-1, the padding bits
consist of a 1 followed by 0s, except the final 8-bytes are a big-endian number representing the length of the message.
4 SHA-1‘s IV is 67452301 EFCDAB89 98BADCFE 10325476 C3D2E1F0, which you’ll observe is little-endian counting from 0 to
F, then back from F to 0, then alternating between counting from 3 to 0 and C to F. It’s
considered good practice when developing a new cryptographic system to ensure that the hard-coded cryptographic primitives are simple, logical, independently-discoverable numbers like
simple sequences and well-known mathematical constants. This helps to prove that the inventor isn’t “hiding” something in there, e.g. a mathematical weakness that depends on a
specific primitive for which they alone (they hope!) have pre-calculated an exploit. If that sounds paranoid, it’s worth knowing that there’s plenty of evidence that various spy
agencies have deliberately done this, at various points: consider the widespread exposure of the BULLRUN programme and its likely influence on Dual EC DRBG.
5 The padding characters I’ve used aren’t accurate, just representative. But there’s the
right number of them!
6 You shouldn’t do this: you’ll cause yourself many headaches in the long run. But you
could.
7 It’s also not always obvious which inputs are included in hash generation and how
they’re manipulated: if you’re actually using this technique adversarily, be prepared to do a little experimentation.
8 In this example, the hash operates over a single block, but the exact same principle
applies regardless of the number of blocks.
9 Imagining the implementation of a nontrivial hashing algorithm, the predictability of
whose output makes their HMAC vulnerable to a length extension attack, is left as an exercise for the reader.
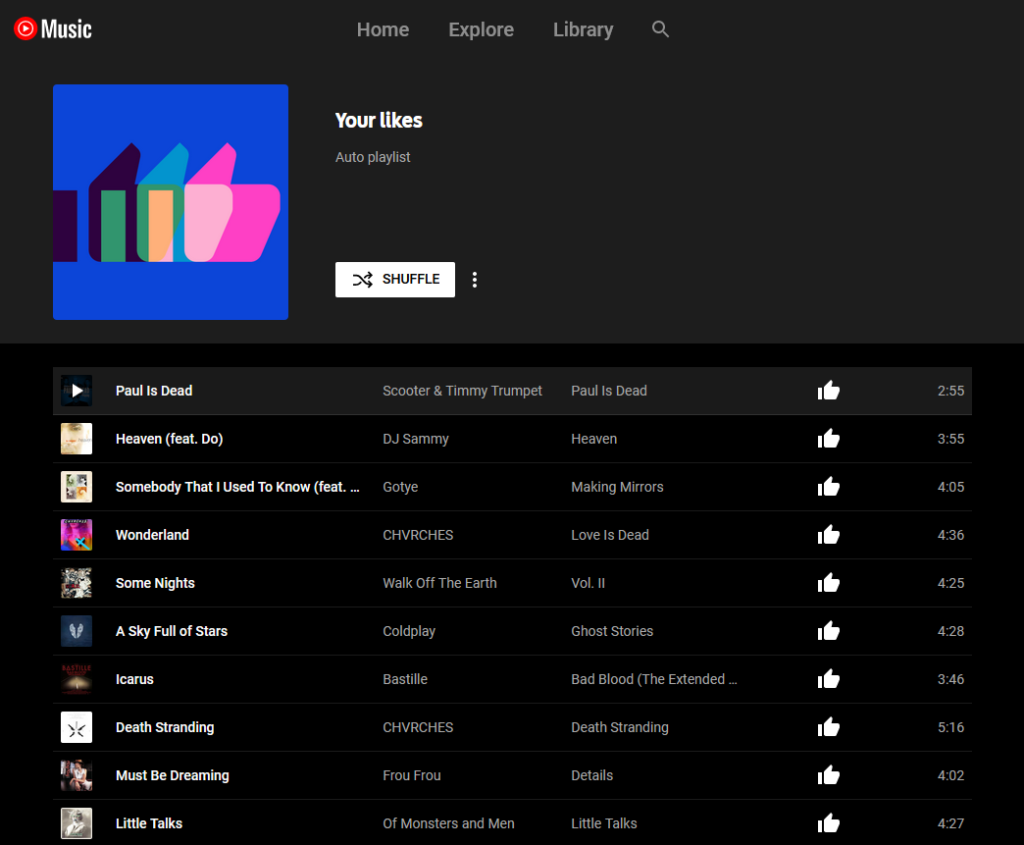
A year and a half ago I came up with a technique for intercepting the “shuffle” operation
on jigsaw website Jigidi, allowing players to force the pieces to appear in a consecutive “stack” for ludicrously easy solving. I did this
partially because I was annoyed that a collection of geocaches near me used Jigidi puzzles as a barrier to their coordinates1…
but also because I enjoy hacking my way around artificially-imposed constraints on the Web (see, for example, my efforts last week to circumvent region-blocking on radio.garden).
My solver didn’t work for long: code changes at Jigidi’s end first made it harder, then made it impossible, to use the approach I suggested. That’s fine by me – I’d already got what I
wanted – but the comments thread on that post suggests that there’s
a lot of people who wish it still worked!2
And so I ignored the pleas of people who wanted me to re-develop a “Jigidi solver”. Until recently, when I once again needed to solve a jigsaw puzzle in order to find a geocache’s
coordinates.
Making A Jigidi Helper
Rather than interfere with the code provided by Jigidi, I decided to take a more-abstract approach: swapping out the jigsaw’s image for one that would be easier.
This approach benefits from (a) having multiple mechanisms of application: query interception, DNS hijacking, etc., meaning that if one stops working then another one can be easily
rolled-out, and (b) not relying so-heavily on the structure of Jigidi’s code (and therefore not being likely to “break” as a result of future upgrades to Jigidi’s platform).
It’s not as powerful as my previous technique – more a “helper” than a “solver” – but it’s good enough to shave at least half the time off that I’d otherwise spend solving a Jigidi
jigsaw, which means I get to spend more time out in the rain looking for lost tupperware. (If only geocaching were even the weirdest of my hobbies…)
How To Use The Jigidi Helper
To do this yourself and simplify your efforts to solve those annoying “all one colour” or otherwise super-frustrating jigsaw puzzles, here’s what you do:
Visit a Jigidi jigsaw. Do not be logged-in to a Jigidi account.
Open your browser’s debug tools (usually F12). In the Console tab, paste it and press enter. You can close your debug tools again (F12) if you like.
Press Jigidi’s “restart” button, next to the timer. The jigsaw will restart, but the picture will be replaced with one that’s easier-to-solve than most, as described below.
Once you solve the jigsaw, the image will revert to normal (turn your screen around and show off your success to a friend!).
What makes it easier to solve?
The replacement image has the following characteristics that make it easier to solve than it might otherwise be:
Every piece has written on it the row and column it belongs in.
Every “column” is striped in a different colour.
Striped “bands” run along entire rows and columns.
To solve the jigsaw, start by grouping colours together, then start combining those that belong in the same column (based on the second digit on the piece). Join whole or partial
columns together as you go.
I’ve been using this technique or related ones for over six months now and no code changes on Jigidi’s side have impacted upon it at all, so it’s probably got better longevity than the
previous approach. I’m not entirely happy with it, and you might not be either, so feel free to fork my code and improve it: the legiblity of the numbers is sometimes suboptimal, and
the colour banding repeats on larger jigsaws which I’d rather avoid. There’s probably also potential to improve colour-recognition by making the colour bands span the gaps
between rows or columns of pieces, too, but more experiments are needed and, frankly, I’m not the right person for the job. For the second time, I’m going to abandon a tool
that streamlines Jigidi solving because I’ve already gotten what I needed out of it, and I’ll leave it up to you if you want to come up with an improvement and share it with the
community.
Footnotes
1 As I’ve mentioned before, and still nobody believes me: I’m not a fan of jigsaws! If you
enjoy them, that’s great: grab a bucket of popcorn and a jigsaw and go wild… but don’t feel compelled to share either with me.
2 The comments also include asuper-helpful person called Rich who’s been manually
solving people’s puzzles for them, and somebody called Perdita
who “could be my grandmother” (except: no) with whom I enjoyed a
conversation on- and off-line about the ethics of my technique. It’s one of the most-popular comment threads my blog has ever seen.
I must be the last person on Earth to have heard about radio.garden (thanks
Pepsilora!), a website that uses a “globe” interface to let you tune in to radio stations around the globe. But I’d only used it for a couple of minutes before I discovered that
there are region restrictions in place. Here in the UK, and perhaps elsewhere, you can’t listen to stations in other countries without
using a VPN or similar tool… which might introduce a different region’s restrictions!
Install this userscript;
it’s hacky – I threw it together in under half an hour – but it seems to work!
My approach is super lazy and simply injects a second audio player – which ignores region restrictions – below the original.
How does this work and how did I develop it?
For those looking to get into userscripting, here’s a quick tutorial on what I did to develop this bypass.
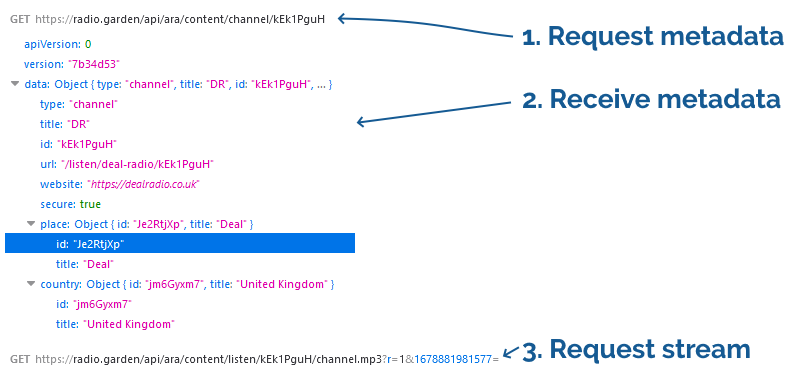
First, I played around with radio.garden for a bit to get a feel for what it was doing. I guessed that it must be tuning into a streaming URL when you select a radio station, so I opened by browser’s debugger on the Network tab and looked at what happened when I clicked on a “working”
radio station, and how that differed when I clicked on a “blocked” one:
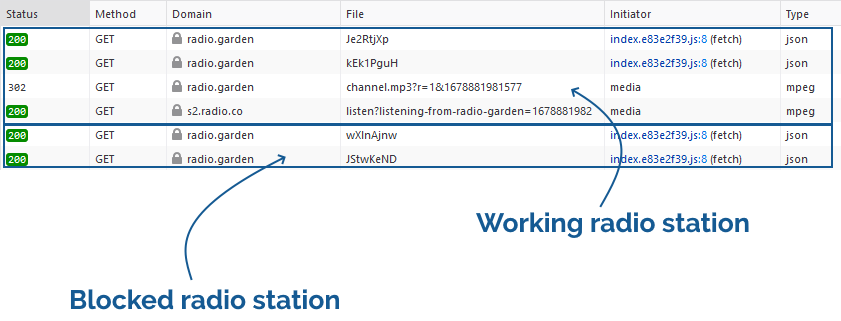
When connecting to a station, a request is made for some JSON that contains station metadata. Then, for a working
station, a request is made for an address like /api/ara/content/listen/[ID]/channel.mp3. For a blocked station, this request isn’t made.
I figured that the first thing I’d try would be to get the [ID] of a station that I’m not permitted to listen to and manually try the URL to see if it was actually blocked, or merely not-being-loaded. Looking at a working station, I first found the ID in the
JSON response and I was about to extract it when I noticed that it also appeared in the request for the
JSON: that’s pretty convenient!
My hypothesis was
that the “blocking” is entirely implemented in the front-end: that the JavaScript code that makes the pretty bits work is looking at the “country” data that’s returned and using that to
decide whether or not to load the audio stream. That provides many different ways to bypass it, from manipulating the JavaScript to remove that functionality, to altering the
JSON response so that every station appears to be in the user’s country, to writing some extra code that intercepts the
request for the metadata and injects an extra audio player that doesn’t comply with the regional restrictions.
But first I needed to be sure that there wasn’t some actual e.g. IP-based blocking on the streams. To do this, first I took the
/api/ara/content/listen/[ID]/channel.mp3 address of a known-working station and opened it in VLC using Media
> Open Network Stream…. That worked. Then I did the same thing again, but substituted the [ID] part of the address with the ID of a “blocked” station.
VLC happily started spouting French to me: the bypass would, in theory, work!
Next, I needed to get that to work from within the site itself. It’s implemented in React, which is a pig to inject code into because it uses horrible identifiers for
DOM elements. But of course I knew that there’d be this tell-tale fetch request for the station metadata that I
could tap into, so I used this technique to override the native fetch method and
replace it with my own “wrapper” that logged the stream address for any radio station I clicked on. I tested the addresses this produced using my browser.
That all worked nicely, so all I needed to do now was to use those addresses rather than simply logging them. Rather that get into the weeds reverse-engineering the built-in
player, I simply injected a new <audio> element after it and pointed it at the correct address, and applied a couple of CSS tweaks to make it fit in nicely.
The only problem was that on UK-based radio stations I’d now hear a slight echo, because the original player was still working. I
could’ve come up with an elegant solution to this, I’m sure, but I went for a quick-and-dirty hack: I used res.json() to obtain the body of the metadata response… which
meant that the actual code that requested it would no longer be able to get it (you can only decode the body of a fetch response once!). radio.garden’s own player treats this as an
error and doesn’t play that radio station, but my new <audio> element still plays it perfectly well.
It’s not pretty, but it’s functional. You can read the finished source code on Github. I don’t anticipate
that I’ll be maintaining this script so if it stops working you’ll have to fix it yourself, and I have no intention of “finishing” it by making it nicer or prettier. I just wanted to
share in case you can learn anything from my approach.
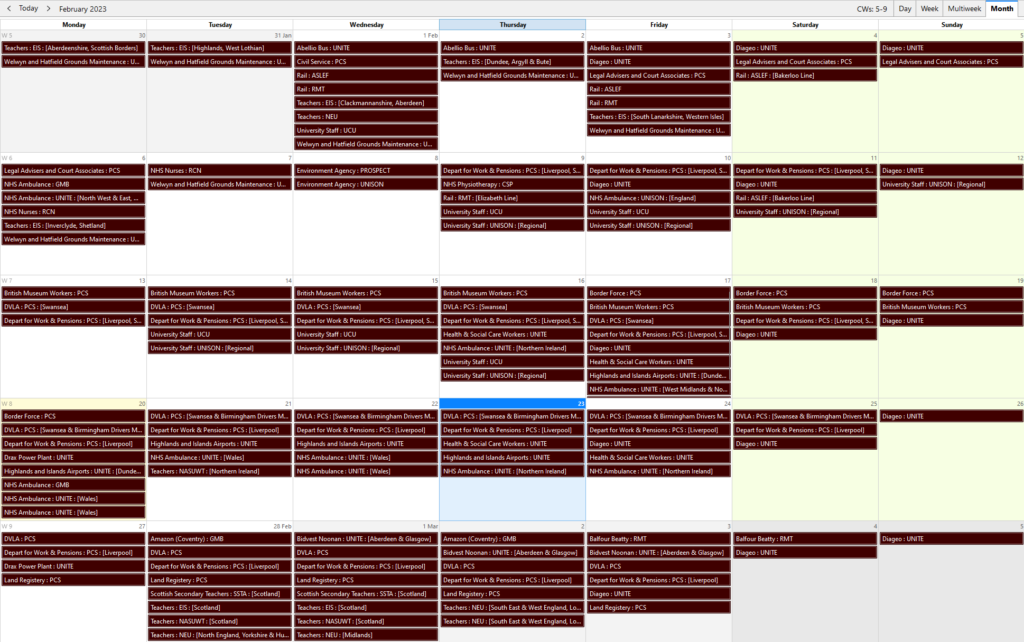
My work colleague Simon was looking for a way to add all of the
upcoming UK strike action to their calendar, presumably so they know when not to try to catch a bus or require an ambulance or maybe
just so they’d know to whom they should be giving support on any particular day. Thom was able to suggest a
few places to see lists of strikes, such as this BBC News page and the comprehensive strikecalendar.co.uk, but neither provided a
handy machine-readable feed.
Gosh, there’s a lot of strikes going on. ✊
If only they knew somebody who loves an excuse to throw a screen-scraper together. Oh wait, that’s me!
I threw together a 36-line Ruby program that extracts all the data from strikecalendar.co.uk and outputs an
.ics file. I guess if you wanted you could set it up to automatically update the file a couple of times a day and host it at a URL that people can subscribe to; that’s an exercise left for the reader.
If you just want a one-off import based on the state-of-play right now, though, you can save this .ics file to your computer
and import it to your calendar. Simple.
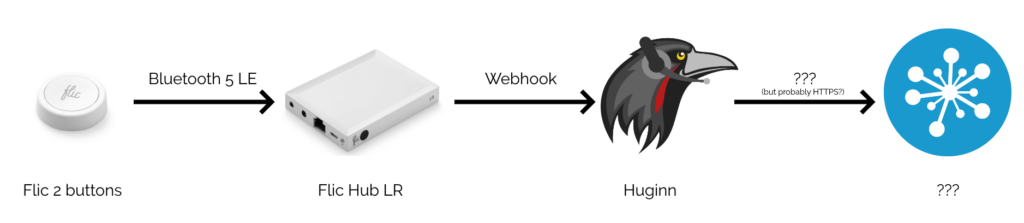
I’ve been playing with a Flic Hub LR and some Flic 2 buttons. They’re “smart home” buttons, but for me they’ve got a killer selling point: rather than
locking you in to any particular cloud provider (although you can do this if you want), you can directly program the hub. This means you can produce smart integrations
that run completely within the walls of your house.
Here’s some things I’ve been building:
Prerequisite: Flic Hub to Huginn connection
Step 1. Enable SDK access. Check!
I run a Huginn instance on our household NAS. If
you’ve not come across it before, Huginn is a bit like an open-source IFTTT: it’s got a steep
learning curve, but it’s incredibly powerful for automation tasks. The first step, then, was to set up my Flic Hub LR to talk to Huginn.
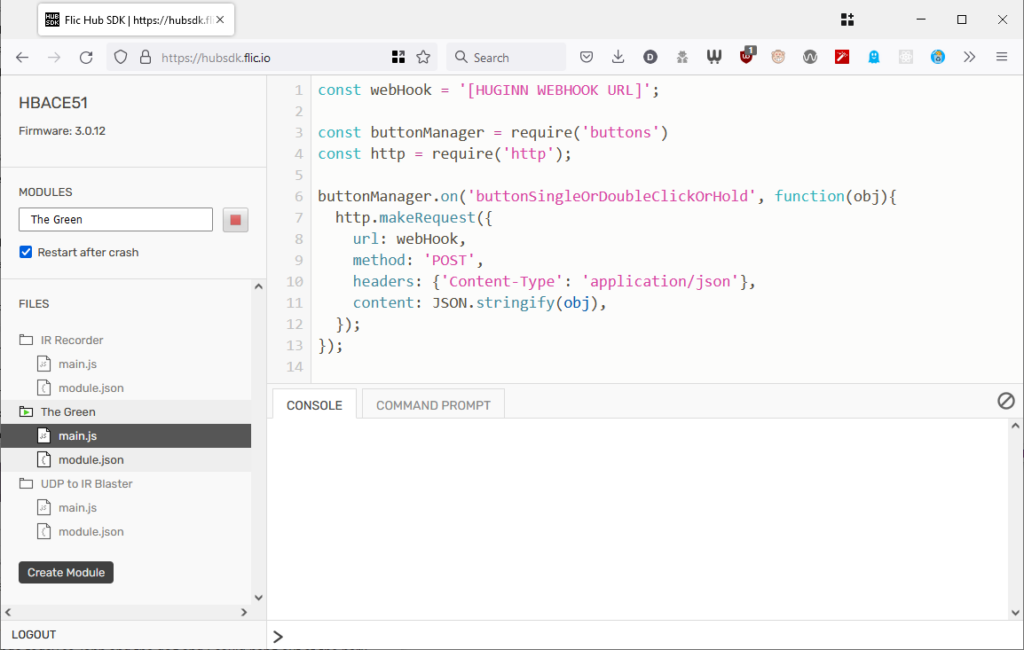
Checking ‘Restart after crash’ seems to help ensure that the script re-launches after e.g. a power cut. Need
the script?
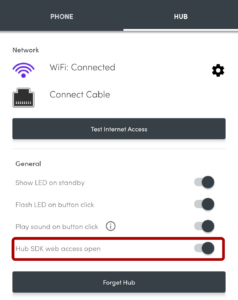
This was pretty simple: all I had to do was switch on “Hub SDK web access open” for the hub using the Flic app,
then use the the web SDK to add this script to the hub. Now whenever a
button was clicked, double-clicked, or held down, my Huginn installation would receive a webhook ping.
Depending on what you have Huginn do “next”, this kind of set-up works completely independently of “the cloud”. (Your raven can fly into the clouds if you really want.)
For convenience, I have all button-presses sent to the same Webhook, and use Trigger Agents to differentiate between buttons and press-types. This means I can re-use
functionality within Huginn, e.g. having both a button press and some other input trigger a particular action.
You’ve Got Mail!
By our front door, we have “in trays” for each of Ruth, JTA and I, as well as one for the
bits of Three Rings‘ post that come to our house. Sometimes post sits in the in-trays for a long time because people don’t think to check
them, or don’t know that something new’s been added.
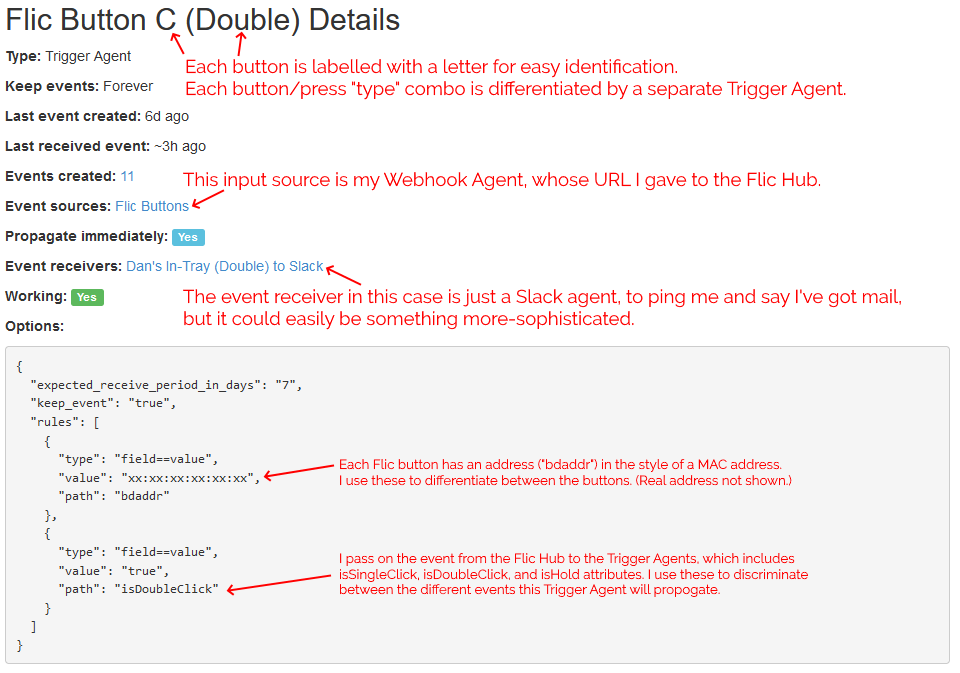
I configured Huginn with a Trigger Agent to receive events from my webhook and filter down to just single clicks on specific buttons. The events emitted by these triggers are used to
notify in-tray owners.
Once you’ve made three events for your first button, you can copy-paste from then on.
In my case, I’ve got pings being sent to mail recipients via Slack, but I could equally well be integrating to other (or additional) endpoints or even
performing some conditional logic: e.g. if it’s during normal waking hours, send a Pushbullet notification to the recipient’s phone, otherwise
send a message to an Arduino to turn on an LED strip along the top of the recipient’s in-tray.
I’m keeping it simple for now. I track three kinds of events (click = “post in your in-tray”, double-click = “I’ve cleared my in-tray”, hold = “parcel wouldn’t fit in your in-tray: look
elsewhere for it”) and don’t do anything smarter than send notifications. But I think it’d be interesting to e.g. have a counter running so I could get a daily reminder (“There
are 4 items in your in-tray.”) if I don’t touch them for a while, or something?
Remember the Milk!
Following the same principle, and with the hope that the Flic buttons are weatherproof enough to work in a covered outdoor area, I’ve fitted one… to the top of the box our milkman
delivers our milk into!
The handle on the box was almost exactly the right size to stick a Flic button to! But it wasn’t flat enough until I took a file to it.
Most mornings, our milkman arrives by 7am, three times a week. But some mornings he’s later – sometimes as late as 10:30am, in extreme cases. If he comes during the school run the milk
often gets forgotten until much later in the day, and with the current weather that puts it at risk of spoiling. Ironically, the box we use to help keep the milk cooler for longer on
the doorstep works against us because it makes the freshly-delivered bottles less-visible.
Now that I had the technical infrastructure already in place, honestly the hardest part of this project was matching the font used in Milk &
More‘s logo.
I’m yet to see if the milkman will play along and press the button when he drops off the milk, but if he does: we’re set! A second possible bonus is that the kids love doing anything
that allows them to press a button at the end of it, so I’m optimistic they’ll be more-willing to add “bring in the milk” to their chore lists if they get to double-click the button to
say it’s been done!
Future Plans
I’m still playing with ideas for the next round of buttons. Could I set something up to streamline my work status, so my colleagues know when I’m not to be disturbed, away from my desk,
or similar? Is there anything I can do to simplify online tabletop roleplaying games, e.g. by giving myself a desktop “next combat turn” button?
My Flic Hub is mounted behind a bookshelf in the living room, with only its infrared transceiver exposed. 20p for scale: we don’t keep a 20p piece stuck to the side of the bookcase
all the time.
I’m quite excited by the fact that the Flic Hub can interact with an infrared transceiver, allowing it to control televisions and similar devices: I’d love to be able to use the volume
controls on our media centre PC’s keyboard to control our TV’s soundbar: and because the Flic Hub can listen for UDP packets, I’m hopeful that something as simple as AutoHotkey can make this possible.
Or perhaps I could make a “universal remote” for our house, accessible as a mobile web app on our internal Intranet, for those occasions when you can’t even be bothered to stand up to
pick up the remote from the other sofa. Or something that switched the TV back to the media centre’s AV input when consoles were powered-down, detected by their network activity? (Right
now the TV automatically switches to the consoles when they’re powered-on, but not back again afterwards, and it bugs me!)
It feels like the only limit with these buttons is my imagination, and that’s awesome.
tl;dr? Just want instructions on how to solve Jigidi puzzles really fast with the help of your browser’s dev tools? Skip to that bit.
This approach doesn’t work any more. Want to see one that still does (but isn’t quite so automated)? Here you go!
I don’t enjoy jigsaw puzzles
I enjoy geocaching. I don’t enjoy jigsaw puzzles. So mystery caches that require you to solve an online jigsaw puzzle in order to get the coordinates really
don’t do it for me. When I’m geocaching I want to be outdoors exploring, not sitting at my computer gradually dragging pixels around!
Many of these mystery caches use Jigidi to host these jigsaw puzzles. An earlier version of Jigidi was auto-solvable with a userscript, but the service has continued to be developed and evolve and the current version works quite hard to
make it hard for simple scripts to solve. For example, it uses a WebSocket connection to telegraph back to the server how pieces are moved around and connected to one another and the
server only releases the secret “you’ve solved it” message after it detects that the pieces have been arranged in the appropriate relative configuration.
If there’s one thing I enjoy more than jigsaw puzzles – and as previously established there are about a billion things I enjoy more than jigsaw puzzles – it’s reverse-engineering a
computer system to exploit its weaknesses. So I took a dive into Jigidi’s client-side source code. Here’s what it does:
Get from the server the completed image and the dimensions (number of pieces).
Cut the image up into the appropriate number of pieces.
Shuffle the pieces.
Establish a WebSocket connection to keep the server up-to-date with the relative position of the pieces.
Start the game: the player can drag-and-drop pieces and if two adjacent pieces can be connected they lock together. Both pieces have to be mostly-visible (not buried under other
pieces), presumably to prevent players from just making a stack and then holding a piece against each edge of it to “fish” for its adjacent partners.
I spent some time tracing call stacks to find this line… only to discover that it’s one of only four lines to actually contain the word “shuffle” and I could have just searched for
it…
Looking at that process, there’s an obvious weak point – the shuffling (point 3) happens client-side, and before the WebSocket sync begins. We could override the
shuffling function to lay the pieces out in a grid, but we’d still have to click each of them in turn to trigger the connection. Or we could skip the shuffling entirely and just leave
the pieces in their default positions.
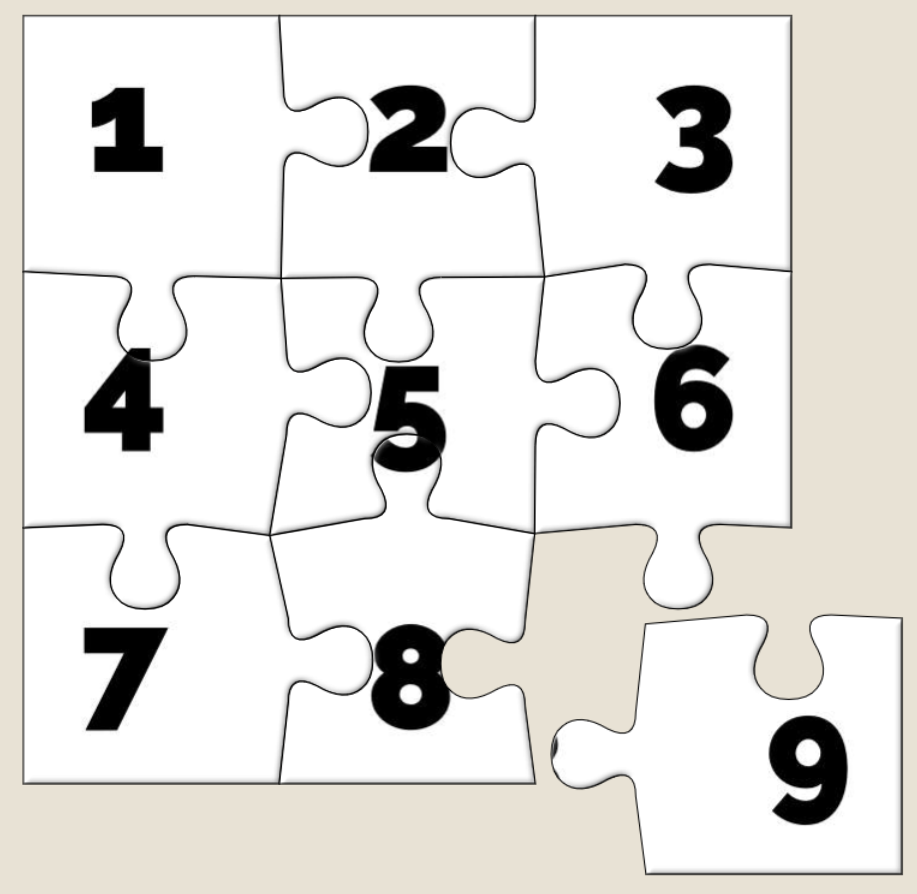
An unshuffled jigsaw appears as a stack, as if each piece from left to right and then top to bottom were placed one at a time into a pile.
And what are the default positions? It’s a stack with the bottom-right jigsaw piece on the top, the piece to the left of it below it, then the piece to the left of that and son on
through the first row… then the rightmost piece from the second-to-bottom row, then the piece to the left of that, and so on.
That’s… a pretty convenient order if you want to solve a jigsaw. All you have to do is drag the top piece to the right to join it to the piece below that. Then move those two to the
right to join to the piece below them. And so on through the bottom row before moving back – like a typewriter’s carriage return – to collect the second-to-bottom row and so on.
How can I do this?
If you’d like to cheat at Jigidi jigsaws, this approach works as of the time of writing. I used Firefox, but the same basic approach should work with virtually any modern desktop web
browser.
Go to a Jigidi jigsaw in your web browser.
Pop up your browser’s developer tools (F12, usually) and switch to the Debugger tab. Open the file game/js/release.js and uncompress it by pressing the
{} button, if necessary.
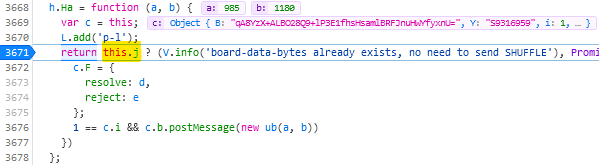
Find the line where the code considers shuffling; right now for me it’s like 3671 and looks like this:
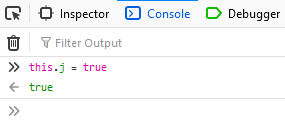
return this.j ? (V.info('board-data-bytes already exists, no need to send SHUFFLE'), Promise.resolve(this.j)) : new Promise(function (d, e) {
I spent some time tracing call stacks to find this line… only to discover that it’s one of only four lines to actually contain the word “shuffle” and I could have just searched
for it…
Set a breakpoint on that line by clicking its line number.
Restart the puzzle by clicking the restart button to the right of the timer. The puzzle will reload but then stop with a “Paused on breakpoint” message. At this point the
application is considering whether or not to shuffle the pieces, which normally depends on whether you’ve started the puzzle for the first time or you’re continuing a saved puzzle from
where you left off.
In the developer tools, switch to the Console tab.
Type: this.j = true (this ensures that the ternary operation we set the breakpoint on will resolve to the true condition, i.e. not shuffle the pieces).
Press the play button to continue running the code from the breakpoint. You can now close the developer tools if you like.
Solve the puzzle as described/shown above, by moving the top piece on the stack slightly to the right, repeatedly, and then down and left at the end of each full row.
Update 2021-09-22:Abraxas observes that Jigidi have changed
their code, possibly in response to this shortcut. Unfortunately for them, while they continue to perform shuffling on the client-side they’ll always be vulnerable to this kind of
simple exploit. Their new code seems to be named not release.js but given a version number; right now it’s 14.3.1977. You can still expand it in the same way,
and find the shuffling code: right now for me this starts on line 1129:
Put a breakpoint on line 1129. This code gets called twice, so the first time the breakpoint gets hit just hit continue and play on until the second time. The second time it gets hit,
move the breakpoint to line 1130 and press continue. Then use the console to enter the code d = a.G and continue. Only one piece of jigsaw will be shuffled; the rest will
be arranged in a neat stack like before (I’m sure you can work out where the one piece goes when you get to it).
Update 2023-03-09: I’ve not had time nor inclination to re-“break” Jigidi’s shuffler, but on the rare ocassions I’ve
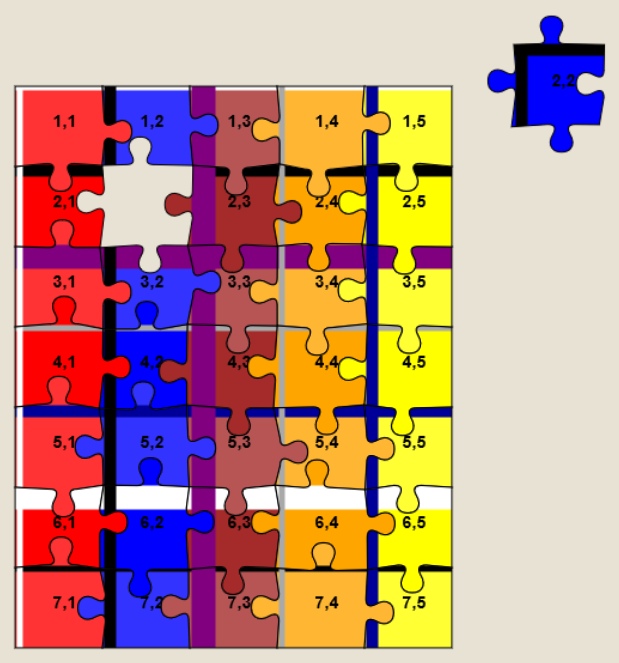
needed to solve a Jigidi, I’ve come up with a technique that replaces a jigsaw’s pieces with ones that each
show the row and column number they belong to, as well as colour-coding the rows and columns and drawing horizontal and vertical bars to help visual alignment. It makes the process
significantly less-painful. It’s still pretty buggy code though and I end up tweaking it each and every time I use it, but it certainly works and makes jigsaws that lack clear visual
markers (e.g. large areas the same colour) a lot easier.
Among Twitter’s growing list of faults over the years are various examples of its increasing divergence from open Web standards and developer-friendly endpoints. Do you remember when
you used to be able to subscribe to somebody’s feed by RSS? When you could see who follows somebody without first logging in?
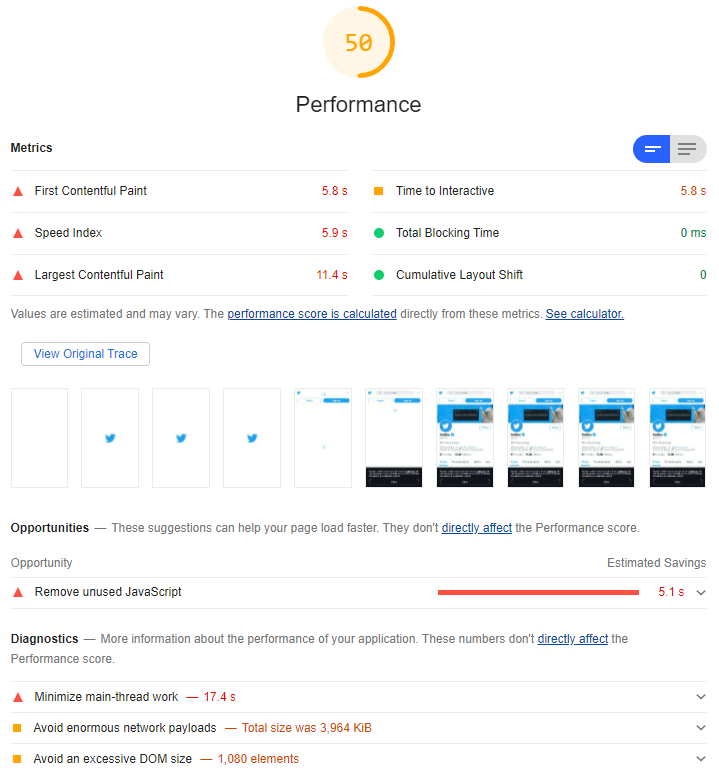
When they were still committed to progressive enhancement and didn’t make your browser download ~5MB of Javascript or else not show any content whatsoever? Feels like a long time ago,
now.
For one of the most-popular 50 websites in the world, this score is frankly shameful.
But those complaints aside, the thing that bugged me most this week was how much harder they’ve made it to programatically get access to things that are publicly accessible via web
pages. Like avatars, for example!
If you’re a human and you want to see the avatar image associated with a given username, you can go to twitter.com/that-username and – after you’ve waited
a bit for all of the mandatory JavaScript to download and run (I hope you’re not on a metered connection!) – you’ll see a picture of the user, assuming they’ve uploaded one and not made
their profile private. Easy.
If you’re a computer and you want to get the avatar image, it used to be just as easy; just go to
twitter.com/api/users/profile_image/that-username and you’d get the image. This was great if you wanted to e.g. show a Facebook-style facepile of images of people who’d retweeted your content.
But then Twitter removed that endpoint and required that computers log in to Twitter, so a clever developer made
a service that fetched avatars for you if you went to e.g. twivatar.glitch.com/that-username.
You want to that image? Well you’ll need a Twitter account, a developer account, an OAuth token set, a stack of code…
Recently, I needed a one-off program to get the avatars associated with a few dozen Twitter usernames.
First, I tried the easy way: find a service that does the work for me. I’d used avatars.io before but it’s died, presumably because (as I soon discovered) Twitter had made
things unnecessarily hard for them.
Second, I started looking at the Twitter API
documentation but it took me in the region of 30-60 seconds before I said “fuck that noise” and decided that the set-up overhead in doing things the official way simply wasn’t
justified for my simple use case.
So I decided to just screen-scrape around the problem. If a human can just go to the web page and see the
image, a computer pretending to be a human can do exactly the same. Let’s do this:
The code is ludicrously simple. It took less time, energy, and code to write this than to follow Twitter’s “approved” procedure. You can download the code via Gist.
Given that I only needed to run it once, on a finite list of accounts, I maintain that my approach was probably kinder on their servers than just manually going to every page
and saving the avatar from it. But if you set up a service that uses this approach then you’ll certainly piss off somebody at Twitter and history shows that they’ll take their displeasure out on you without warning.
This output shows the avatar URLs of a half a dozen Twitter accounts. It took minutes to write the code and takes seconds
to run, but if I’d have done it the “right” way I’d still be unnecessarily wading through Twitter’s sprawling documentation.
But it works. It was fast and easy and I got what I was looking for.
And the moral of the story is: if you make an API and it’s terrible, don’t be surprised if people screen-scape your
service instead. (You can’t spell “scraping” without “API”, amirite?)
Cellebrite makes software to automate physically extracting and indexing data from mobile devices. They exist within the grey – where enterprise branding joins together with the
larcenous to be called “digital intelligence.” Their customer list has included authoritarian regimes in Belarus, Russia, Venezuela, and China; death squads in Bangladesh; military
juntas in Myanmar; and those seeking to abuse and oppress in Turkey, UAE, and elsewhere. A few months ago, they announced
that they added Signal support to their software.
Their products have often been linked to the persecution of imprisoned journalists and activists around the world, but less has been written about what their software actually
does or how it works. Let’s take a closer look. In particular, their software is often associated with bypassing security, so let’s take some time to examine the security of
their own software.
Recently Moxie, co-author of the Signal Protocol, came into possession of a Cellebrite Extraction Device (phone cracking kit used by law enforcement as well as by oppressive regimes who
need to clamp down on dissidents) which “fell off a truck” near him. What an amazing coincidence! He went on to report, this week, that he’d partially reverse-engineered the system,
discovering copyrighted code from Apple – that’ll go down well! – and, more-interestingly, unpatchedvulnerabilities. In a demonstration video, he goes on to show that
a carefully crafted file placed on a phone could, if attacked using a Cellebrite device, exploit these vulnerabilities to take over the forensics equipment.
Obviously this is a Bad Thing if you’re depending on that forensics kit! Not only are you now unable to demonstrate that the evidence you’re collecting is complete and accurate, because
it potentially isn’t, but you’ve also got to treat your equipment as untrustworthy. This basically makes any evidence you’ve collected inadmissible in many courts.
Moxie goes on to announce a completely unrelated upcoming feature for Signal: a minority of functionally-random installations will create carefully-crafted files on their
devices’ filesystem. You know, just to sit there and look pretty. No other reason:
In completely unrelated news, upcoming versions of Signal will be periodically fetching files to place in app storage. These files are never used for anything inside Signal and never
interact with Signal software or data, but they look nice, and aesthetics are important in software. Files will only be returned for accounts that have been active installs for some
time already, and only probabilistically in low percentages based on phone number sharding. We have a few different versions of files that we think are aesthetically pleasing, and
will iterate through those slowly over time. There is no other significance to these files.
Max has produced a list of “naughty strings”: things you might try injecting into your systems along with any fuzz testing you’re doing to check for common errors in escaping,
processing, casting, interpreting, parsing, etc. The copy above is heavily truncated: the list is long!
It’s got a lot of the things in it that you’d expect to find: reserved keywords and filenames, unusual or invalid unicode codepoints, tests for the Scunthorpe Problem, and so on. But perhaps my favourite entry is this one, a test for “human injection”:
# Human injection
#
# Strings which may cause human to reinterpret worldview
If you're reading this, you've been in a coma for almost 20 years now. We're trying a new technique. We don't know where this message will end up in your dream, but we hope it works.
Please wake up, we miss you.
My friend still uses a seriously retro digital music player, rather than his phone, to listen to music. It’s not a Walkman or a Minidisc player, I suppose, but it’s still pretty
elderly. But it’s not one of these.
I’m not here to speak about the legality of retaining offline copies of music from streaming services. YouTube Music seems to permit you to do this using their app, but I’ll bet there’s
something in their terms and conditions that specifically prohibits doing so any other way. Not least because Google’s arrangement with rights holders probably stipulates that they
track how many times tracks are played, and using a different player (like my friend’s portable device) would throw that off.
But what I’m interested in is the feasibility. And in answering that question, in explaining how to work out that it’s feasible.
The web interface to YouTube Music shows playlists of songs and streaming is just a click away.
Spoiler: I came up with an approach, and it looks like it works. My friend can fill up their Zune or whatever the hell
it is with their tunes and bop away. But what I wanted to share with you was the underlying technique I used to develop this approach, because it involves skills that as a web
developer I use most weeks. Hold on tight, you might learn something!
youtube-dl can download “playlists” already, but to download a personal playlist requires that you faff about with authentication and it’s a bit of a drag. Just extracting
the relevant metadata from the page is probably faster, I figured: plus, it’s a valuable lesson in extracting data from web pages in general.
Here’s what I did:
Step 1. Load all the data
I noticed that YouTube Music playlists “lazy load”, and you have to scroll down to see everything. So I scrolled to the bottom of the page until I reached the end of the playlist: now
everything was in the DOM, I could investigate it with my inspector.
Step 2. Find each track’s “row”
Using my browser’s debugger “inspect” tool, I found the highest unique-sounding element that seemed to represent each “row”/track. After a little investigation, it looked like
a playlist always consists of a series of <ytmusic-responsive-list-item-renderer> elements wrapped in a <ytmusic-playlist-shelf-renderer>. I tested
this by running document.querySelectorAll('ytmusic-playlist-shelf-renderer ytmusic-responsive-list-item-renderer') in my debug console and sure enough, it returned a number
of elements equal to the length of the playlist, and hovering over each one in the debugger highlighted a different track in the list.
The web application captured right-clicks, preventing the common right-click-then-inspect-element approach… so I just clicked the “pick an element” button in the debugger.
Step 3. Find the data for each track
I didn’t want to spend much time on this, so I looked for a quick and dirty solution: and there was one right in front of me. Looking at each track, I saw that it contained several
<yt-formatted-string> elements (at different depths). The first corresponded to the title, the second to the artist, the third to the album title, and the fourth to
the duration.
Better yet, the first contained an <a> element whose href was the URL of the piece of music.
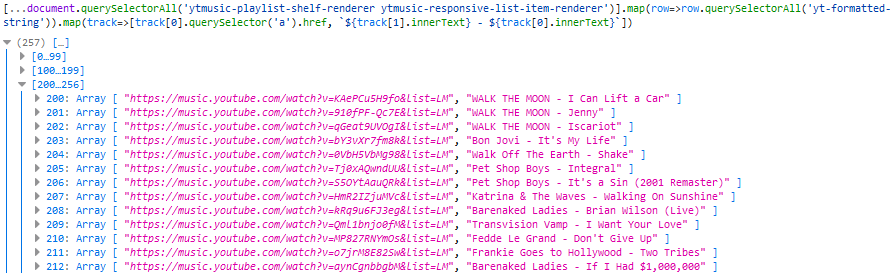
Extracting the URL and the text was as simple as a .querySelector('a').href on the first
<yt-formatted-string> and a .innerText on the others, respectively, so I ran [...document.querySelectorAll('ytmusic-playlist-shelf-renderer
ytmusic-responsive-list-item-renderer')].map(row=>row.querySelectorAll('yt-formatted-string')).map(track=>[track[0].querySelector('a').href, `${track[1].innerText} -
${track[0].innerText}`]) (note the use of [...*] to get an array) to check that I was able to get all the data I needed:
Lots of URLs and the corresponding track names in my friend’s preferred format (me, I like to separate my music into folders
by album, but I suppose I’ve got a music player with more than a floppy disk’s worth of space on it).
Step 4. Sanitise the data
We’re not quite good-to-go, because there’s some noise in the data. Sometimes the application’s renderer injects line feeds into the innerText (e.g. when escaping an
ampersand). And of course some of these song titles aren’t suitable for use as filenames, if they’ve got e.g. question marks in them. Finally, where there are multiple spaces in a row
it’d be good to coalesce them into one. I do some experiments and decide that .replace(/[\r\n]/g, '').replace(/[\\\/:><\*\?]/g, '-').replace(/\s{2,}/g, ' ') does a
good job of cleaning up the song titles so they’re suitable for use as filenames.
I probably should have it fix quotes too, but I’ll leave that as an exercise for the reader.
Step 5. Produce youtube-dl commands
Okay: now we’re ready to combine all of that output into commands suitable for running at a terminal. After a quick dig through the documentation, I decide that we needed the following
switches:
-x to download/extract audio only: it defaults to the highest quality format available, which seems reasomable
-o "the filename.%(ext)s" to specify the output filename but accept the format provided by the quality requirement (transcoding to your preferred format is a
separate job not described here)
--no-playlist to ensure that youtube-dl doesn’t see that we’re coming from a playlist and try to download it all (we have our own requirements of each song’s
filename)
--download-archive downloaded.txt to log what’s been downloaded already so successive runs don’t re-download and the script is “resumable”
The output isn’t pretty, but it’s suitable for copy-pasting into a terminal or command prompt where it ought to download a whole lot of music for offline play.
This isn’t an approach that most people will ever need: part of the value of services like YouTube Music, Spotify and the like is that you pay a fixed fee to stream whatever you like,
wherever you like, obviating the need for a large offline music collection. And people who want to maintain a traditional music collection offline are most-likely to want to do
so while supporting the bands they care about, especially as (with DRM-free digital downloads commonplace) it’s never been
easier to do so.
But for those minority of people who need to play music from their streaming services offline but don’t have or can’t use a device suitable for doing so on-the-go, this kind of approach
works. (Although again: it’s probably not permitted, so be sure to read the rules before you use it in such a way!)
Step 6. Learn something
But more-importantly, the techniques of exploring and writing console Javascript demonstrated are really useful for extracting all kinds of data from web pages (data scraping), writing your own userscripts, and much more. If there’s
one lesson to take from this blog post it’s not that you can steal music on the Internet (I’m pretty sure everybody who’s lived on this side of 1999 knows that by now), but
that you can manipulate the web pages you see. Once you’re viewing it on your computer, a web page works for you: you don’t have to consume a page in the way that the
author expected, and knowing how to extract the underlying information empowers you to choose for yourself a more-streamlined, more-personalised, more-powerful web.
Everything you see when you use “Inspect Element” was already downloaded to your computer, you just hadn’t asked Chrome to show it to you yet. Just like how the cogs were already in
the watch, you just hadn’t opened it up to look.
But let us dispense with frivolous cog talk. Cheap tricks such as “Inspect Element” are used by programmers to try and understand how the website works. This is ultimately futile:
Nobody can understand how websites work. Unfortunately, it kinda looks like hacking the first time you see it.
Thieves didn’t even bother with a London art gallery’s Constable landscape—and they still walked away with $3 million.
This comic is perhaps the best way to enjoy this news story, which describes the theft of £2.4 million during an unusual… let’s call it an “art heist”… in 2018. It has many the
characteristics of the kind of heist you’re thinking about: the bad guys got the money, and nobody gets to see the art. But there’s a twist: the criminals never came anywhere near the
painting.
This theft was committed entirely in cyberspace: the victim was tricked into wiring the money to pay for the painting into the wrong account. The art buyer claims that he made
the payment in good faith, though, and that he’s not culpable because it was the seller’s email that must have been hacked. Until it’s resolved, the painting’s not on display, so not
only do the criminals have the cash, the painting isn’t on display.