A not-entirely-theoretical question about open source software licensing came up at work the other day. I thought it was interesting enough to warrant a quick dive into the philosophy of minification, and how it relates to copyleft open source licenses. Specifically: does distributing (only) minified source code violate the GPL?
If you’ve come here looking for a legally-justifiable answer to that question, you’re out of luck. But what I can give you is a (fictional) story:
TheseusJS is slow
TheseusJS is a (fictional) Javascript library designed to be run in a browser. It’s released under the GPLv3 license. This license allows you to download and use TheseusJS for any purpose you like, including making money off it, modifying it, or redistributing it to others… but it requires that if you redistribute it you have to do so under the same license and include the source code. As such, it forces you to share with others the same freedoms you enjoy for yourself, which is highly representative of some schools of open-source thinking.
It’s a great library and it’s used on many websites, but its performance isn’t great. It’s become infamous for the impact it has on the speed of the websites it’s used on, and it’s often the butt of jokes by developers: “Man, this website’s slow. Must be running Theseus!”
The original developer has moved onto his new project, Moralia, and seems uninterested in handling the growing number of requests for improvements. So I’ve decided to fork it and make my own version, FastTheseusJS and work on improving its speed.
FastTheseusJS is fast
I do some analysis and discover the single biggest problem with TheseusJS is that the Javascript file itself is enormous. The original developer kept all of the copious documentation in comments in the file itself, and for some reason it doesn’t even compress well. When you use TheseusJS on a website it takes a painfully long time for a browser to download it, if it’s not precached.
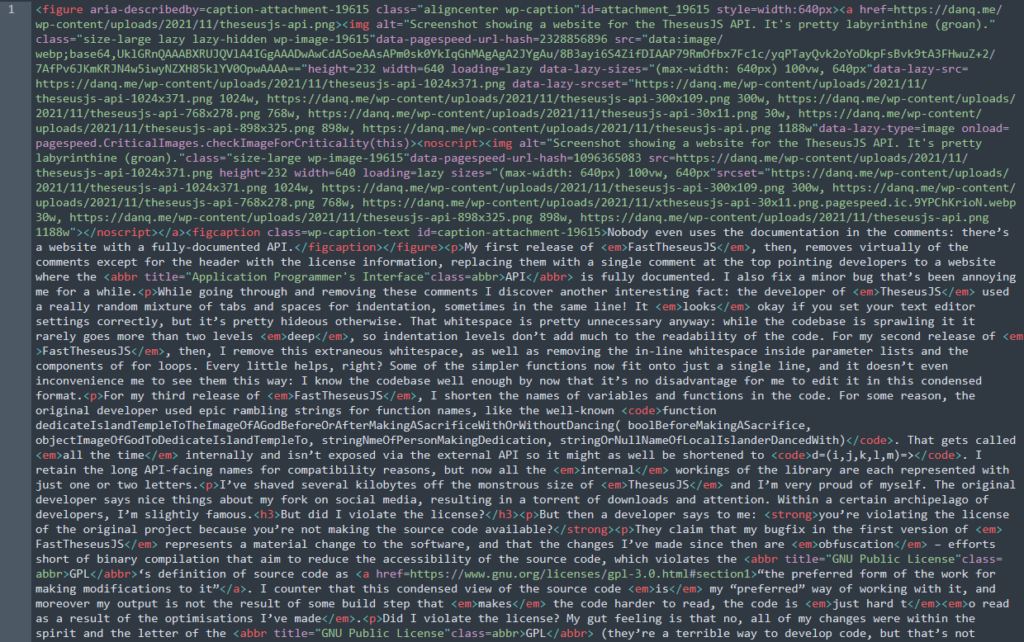
My first release of FastTheseusJS, then, removes virtually of the comments, replacing them with a single comment at the top pointing developers to a website where the API is fully documented. While I’m in there anyway, I also fix a minor bug that’s been annoying me for a while.
v1.1.0 changes
- Forked from TheseusJS v1.0.4
- Fixed issue #1071 (running
mazeSolver()without first connecting<String>component results in endless loop)- Removed all comments: improves performance considerably
I discover another interesting fact: the developer of TheseusJS used a really random mixture of tabs and spaces for indentation, sometimes in the same line! It looks… okay if you set your editor up just right, but it’s pretty hideous otherwise. That whitespace is unnecessary anyway: the codebase is sprawling but it seldom goes more than two levels deep, so indentation levels don’t add much readability. For my second release of FastTheseusJS, then, I remove this extraneous whitespace, as well as removing the in-line whitespace inside parameter lists and the components of for loops. Every little helps, right?
v1.1.1 changes
- Standardised whitespace usage
- Removed unnecessary whitespace
Some of the simpler functions now fit onto just a single line, and it doesn’t even inconvenience me to see them this way: I know the codebase well enough by now that it’s no disadvantage for me to edit it in this condensed format.
In the next version, I shorten the names of variables and functions in the code.
For some reason, the original developer used epic rambling strings for function names, like the well-known function
dedicateIslandTempleToTheImageOfAGodBeforeOrAfterMakingASacrificeWithOrWithoutDancing( boolBeforeMakingASacrifice, objectImageOfGodToDedicateIslandTempleTo,
stringNmeOfPersonMakingDedication, stringOrNullNameOfLocalIslanderDancedWith). That one gets called all the time internally and isn’t exposed via the external
API so it might as well be shortened to d=(i,j,k,l,m)=>. Now all the internal workings of the library
are each represented with just one or two letters.
v1.1.2 changes
- Shortened/standarised non-API variable and function names – improves performance
I’ve shaved several kilobytes off the monstrous size of TheseusJS and I’m very proud. The original developer says nice things about my fork on social media, resulting in a torrent of downloads and attention. Within a certain archipelago of developers, I’m slightly famous.
But did I violate the license?
But then a developer says to me: you’re violating the license of the original project because you’re not making the source code available!

They claim that my bugfix in the first version of FastTheseusJS represents a material change to the software, and that the changes I’ve made since then are obfuscation: efforts short of binary compilation that aim to reduce the accessibility of the source code. This fails to meet the GPL‘s definition of source code as “the preferred form of the work for making modifications to it”. I counter that this condensed view of the source code is my “preferred” way of working with it, and moreover that my output is not the result of some build step that makes the code harder to read, the code is just hard to read as a result of the optimisations I’ve made. In ambiguous cases, whose “preference” wins?
Did I violate the license? My gut feeling is that no, all of my changes were within the spirit and the letter of the GPL (they’re a terrible way to write code, but that’s not what’s in question here). Because I manually condensed the code, did so with the intention that this condensing was a feature, and continue to work directly with the code after condensing it because I prefer it that way… that feels like it’s “okay”.
But if I’d just run the code through a minification tool, my opinion changes. Suppose I’d run minify --output fasttheseus.js theseus.js and then deleted my copy of
theseus.js. Then, making changes to fasttheseus.js and redistributing it feels like a violation to me… even if the resulting code is the same as I’d have
gotten via the “manual” method!
I don’t know the answer (IANAL), but I’ll tell you this: I feel hypocritical for saying one piece of code would not violate the license but another identical piece of code would, based only on the process the developer followed to produce it. If I replace one piece of code at a time with less-readable versions the license remains intact, but if I replace them all at once it doesn’t? That doesn’t feel concrete nor satisfying.
This isn’t an entirely contrived example
This example might seem highly contrived, and that’s because it is. But the grey area between the extremes is where the real questions are. If you agree that redistribution of (only) minified source code violates the GPL, you’re left asking: at what point does the change occur? Code isn’t necessarily minified or not-minified: there are many intermediate steps.
If I use a correcting linter to standardise indentation and whitespace – switching multiple spaces for the appropriate number of tabs, removing excess line breaks etc. (or do the same tasks manually) I’m sure you’d agree that’s fine. If I have it replace whole-function if-blocks with hoisted return statements, that’s probably fine too. If I replace if blocks with ternery operators or remove or shorten comments… that might be fine, but probably depends upon context. At some point though, some way along the process, minification goes “too far” and feels like it’s no longer within the limitations of the license. And I can’t tell you where that point is!
This issue’s even more-complicated with some other licenses, e.g. the AGPL, which extends the requirement to share source code to hosted applications. Suppose I implement a web application that uses an AGPL-licensed library. The person who redistributed it to me only gave me the minified version, but they gave me a web address from which to acquire the full source code, so they’re in the clear. I need to make a small patch to the library to support my service, so I edit it right into the minified version I’ve already got. A user of my hosted application asks for a copy of the source code, so I provide it, including the edited minified library… am I violating the license for not providing the full, unminified version, even though I’ve never even seen it? It seems absurd to say that I would be, but it could still be argued to be the case.
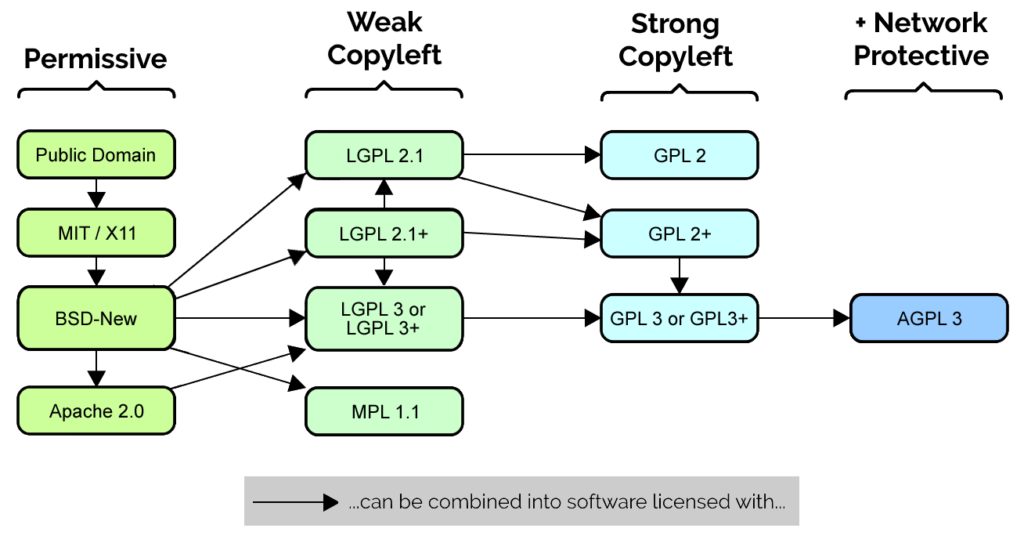
99% of the time, though, the answer’s clear, and the ambiguities shown above shouldn’t stop anybody from choosing to open-source their work under GPL, AGPL (or any other open source license depending on their preference and their community). Perhaps the question of whether minification violates the letter of a copyleft license is one of those Potter Stewart “I know it when I see it” things. It certainly goes against the spirit of the thing to do so deliberately or unnecessarily, though, and perhaps it’s that softer, more-altruistic goal we should be aiming for.