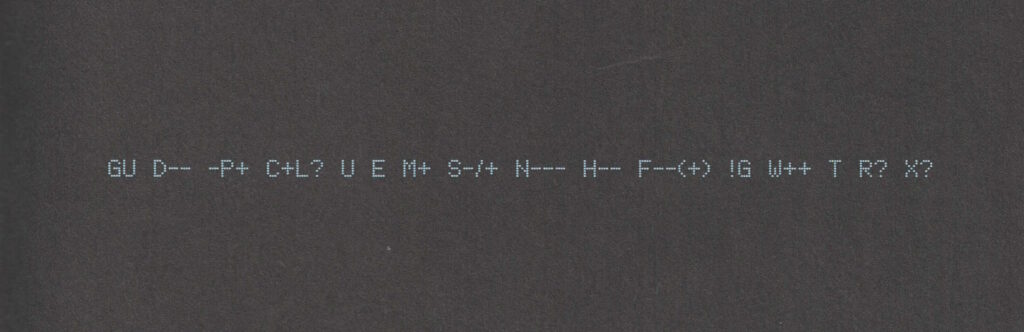I’ve got a (now four-year-old) Unraid NAS called Fox and I’m a huge fan. I particularly love the fact that Unraid can work not only as a NAS, but also as a fully-fledged Docker appliance, enabling me to easily install and maintain all manner of applications.
There isn’t really a generator attached to Fox, just a UPS battery backup. The sign was liberated from our shonky home electrical system.
I was chatting this week to a colleague who was considering getting a similar setup, and he seemed to be taking notes of things he might like to install, once he’s got one. So I figured
I’d round up five of my favourite things to install on an Unraid NAS that:
Don’t require any third-party accounts (low dependencies),
Don’t need any kind of high-powered hardware (low specs), and
Provide value with very little set up (low learning curve).
It’d have been cooler if I’d have secretly written this blog post while sitting alongside said colleague (shh!). But sadly it had to wait until I was home.
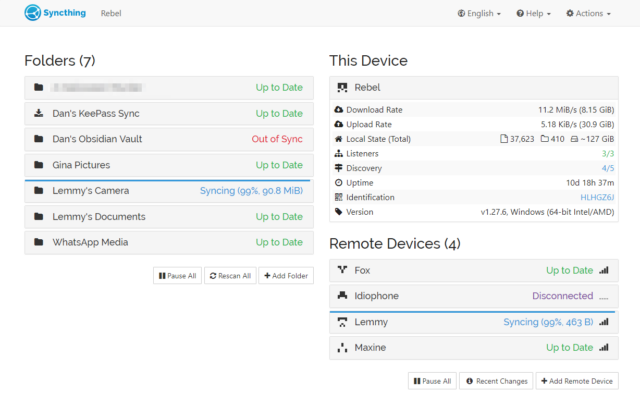
Syncthing’s just an awesome piece of set-and-forget software that facilitates file synchronisation between all of your devices and can also form part of a backup strategy.
Here’s the skinny: you install Syncthing on several devices, then give each the identification key of another to pair them. Now you can add folders on each and “share” them with the
others, and the two are kept in-sync. There’s lots of options for power users, but just as a starting point you can use this to:
Manage the photos on your phone and push copies to your desktop whenever you’re home (like your favourite cloud photo sync service, but selfhosted).
Keep your Obsidian notes in-sync between all your devices (normally costs $4/month).1
Get a copy of the documents from all your devices onto your NAS, for backup purposes (note that sync’ing alone, even with
versioning enabled, is not a good backup: the idea is that you run an actual backup from your NAS!).
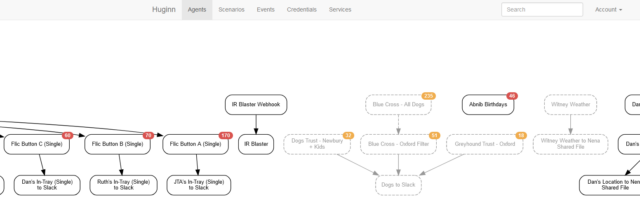
You know IFTTT? Zapier? Services that help you to “automate” things based on inputs and outputs. Huginn’s like that, but selfhosted.
Also: more-powerful.
When we first started looking for a dog to adopt (y’know, before we got this derper), I set up Huginn watchers to monitor the websites of several rescue centres, filter them by some of our criteria, and push
the results to us in real-time on Slack, giving us an edge over other prospective puppy-parents.
The learning curve is steeper than anything else on this list, and I almost didn’t include it for that reason alone. But once you’ve learned your way around its idiosyncrasies and
dipped your toe into the more-advanced Javascript-powered magic it can do, you really begin to unlock its potential.
It couples well with Home Assistant, if that’s your jam. But even without it, you can find yourself automating things you never expected to.
Many of these suggested apps benefit well from you exposing them to the open Web rather than just running them on your LAN,
and an RSS reader is probably the best example (you want to read your news feeds when you’re out and about, right?). What you
need for that is a reverse proxy, and there are lots of guides to doing it super-easily, even if you’re not on a static IP
address.2.
Alternatively you can just VPN in to your home: your router might be able to arrange this, or else Unraid can do it for you!
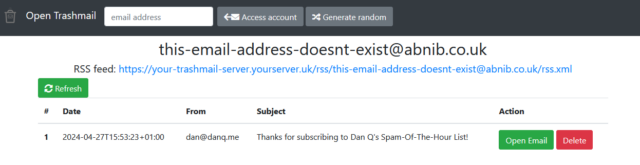
You know how sometimes you need to give somebody your email address but you don’t actually want to. Like: sure, I’d like you to email me a verification code for this download, but I
don’t trust you not to spam me later! What you need is a disposable email address.3
How do you feel about having infinite email addresses that you can make up on-demand (without even having access to a computer), subscribe to by RSS, and never have to see unless you specifically want to.
You just need to install Open Trashmail, point the MX records of a few domain names or subdomains (you’ve got some spare domain names
lying around, right? if not; they’re pretty cheap…) at it, and it will now accept email to any address on those domains. You can make up addresses off the top of your head,
even away from an Internet connection when using a paper-based form, and they work. You can check them later if you want to… or ignore them forever.
Couple it with an RSS reader, or Huginn, or Slack, and you can get a notification or take some action when an email arrives!
Need to give that escape room your email address to get a copy of your “team photo”? Give them a throwaway, pick up the picture when you get home, and then forget you ever gave it
to them.
Company give you a freebie on your birthday if you sign up their mailing list? Sign up 366 times with them and write a Huginn workflow that puts “today’s” promo code into your
Obsidian notetaking app (Sync’d over Syncthing) but filters out everything else.
Suspect some organisation is selling your email address on to third parties? Give them a unique email address that you only give to them and catch them in a honeypot.
It isn’t pretty, but… it doesn’t need to be! Nobody actually sees the admin interface except you anyway.
Plus, it’s just kinda cool to be able to brand your shortlinks with your own name, right? If you follow only one link from this post, let it be to watch this video
that helps explain why this is important: danq.link/url-shortener-highlights.
I run many, many other Docker containers and virtual machines on my NAS. These five aren’t even the “top five” that I
use… they’re just five that are great starters because they’re easy and pack a lot of joy into their learning curve.
And if your NAS can’t do all the above… consider Unraid for your next NAS!
Footnotes
1 I wrote the beginnings of this post on my phone while in the Channel Tunnel and then
carried on using my desktop computer once I was home. Sync is magic.
2 I can’t share or recommend one reverse proxy guide in particular because I set my own up
because I can configure Nginx in my sleep, but I did a quick search and found several that all look good so I imagine you can do the same. You don’t have to do it on day one, though!
Ever wondered why Oxford’s area code is 01865? The story is more-complicated than you’d think.
As a child, I was told that city STD codes were usually associated to the letters that appear on some telephones… but that
wouldn’t make any sense for Oxford’s code!
I’ll share the story on my blog, of course. But before then, I’ll be telling it from the stage of the Jericho Tavern at 21:15 on Wednesday 17 April as
my third(?) appearance at Oxford Geek Nights! So if you’re interested in learning about some of the quirks of UK telephone numbering
history, I can guarantee that this party’s the only one to be at that Wednesday night!
Not your jam? That’s okay: there’s plenty of more-talented people than I who’ll be speaking, about subjects as diverse as quantum computing with QATboxen, bringing your D&D experience to stakeholder management (!), video games
without screens, learnings from the Horizon scandal, and whatever Freyja Domville means by The Unreasonable Effectiveness of the Scientific Method (but I’m seriously excited by that title).
Anyway: I hope you’ll be coming along to Oxford Geek Nights 57 next month, if not to hear me witter on about the
fossils in our telecommunications networks then to enjoy a beer and hear from the amazing speakers I’ll be sharing the stage with. The event’s always a blast, and I’m looking forward to
seeing you there!
This is a video version of my blog post, Length Extension Attack. In it, I talk through the theory of length extension
attacks and demonstrate an SHA-1 length extension attack against an (imaginary) website.
Prefer to watch/listen than read? There’s a vloggy/video version of this post in which I explain all the
key concepts and demonstrate an SHA-1 length extension attack against an imaginary site.
I understood the concept of a length traversal
attack and when/how I needed to mitigate them for a long time before I truly understood why they worked. It took until work provided me an opportunity to play with one in practice (plus reading Ron Bowes’ excellent article on the subject) before I really grokked it.
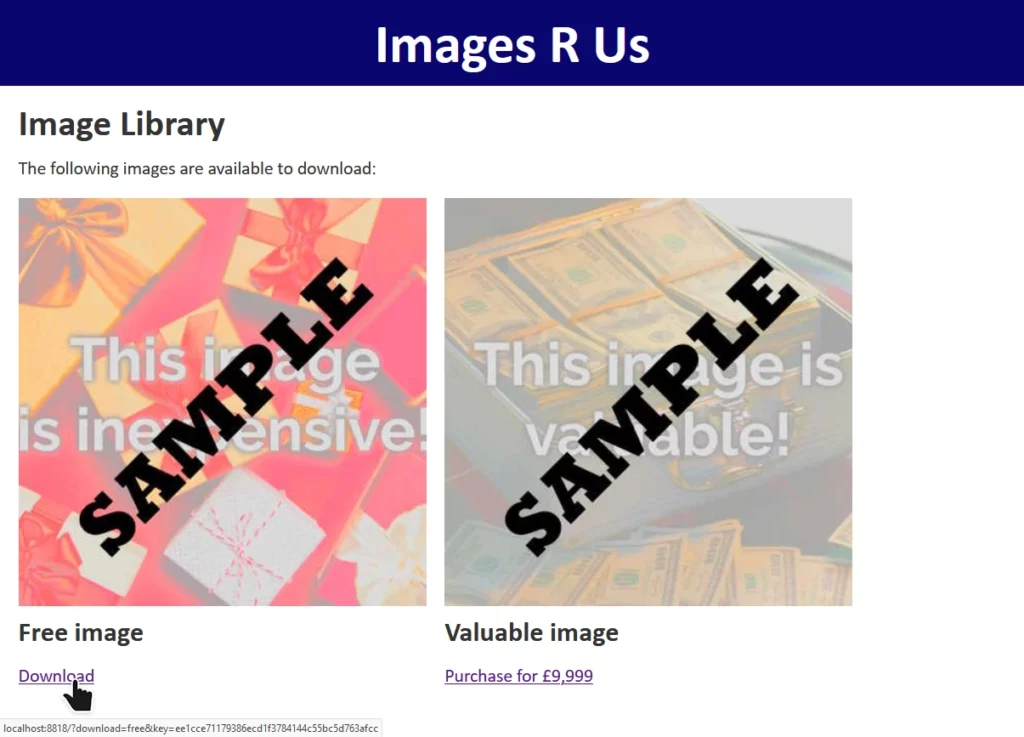
For the demonstration, I’ve built a skeletal stock photography site whose download links are protected by a hash of the link parameters, salted using a secret string stored securely
on the server. Maybe they let authorised people hotlink the images or something.
You can check out the code and run it using the instructions in the repository if you’d like to play along.
Using hashes as message signatures
The site “Images R Us” will let you download images you’ve purchased, but not ones you haven’t. Links to the images are protected by a SHA-1 hash1, generated as follows:
The nature of hashing algorithms like SHA-1 mean that even a small modification to the inputs, e.g. changing one character in
the word “free”, results in a completely different output hash which can be detected as invalid.
When a “download” link is generated for a legitimate user, the algorithm produces a hash which is appended to the link. When the download link is clicked, the same process is followed
and the calculated hash compared to the provided hash. If they differ, the input must have been tampered with and the request is rejected.
Without knowing the secret key – stored only on the server – it’s not possible for an attacker to generate a valid hash for URL parameters of the attacker’s choice. Or is it?
Changing
download=free to download=valuable invalidates the hash, and the request is denied.
Actually, it is possible for an attacker to manipulate the parameters. To understand how, you must first understand a little about how SHA-1 and its siblings actually work:
SHA-1‘s inner workings
The message to be hashed (SECRET_KEY + URL_PARAMS) is cut into blocks of a fixed size.2
The final block is padded to bring it up to the full size.3
A series of operations are applied to the first block: the inputs to those operations are (a) the contents of the block itself, including any padding, and (b) an initialisation
vector defined by the algorithm.4
The same series of operations are applied to each subsequent block, but the inputs are (a) the contents of the block itself, as before, and (b) the output of the previous
block. Each block is hashed, and the hash forms part of the input for the next.
The output of running the operations on the final block is the output of the algorithm, i.e. the hash.
SHA-1 operates on a single block at a time, but the output of processing each block acts as part of the input of the one that
comes after it. Like a daisy chain, but with cryptography.
In SHA-1, blocks are 512 bits long and the padding is a 1, followed by as many 0s as is necessary,
leaving 64 bits at the end in which to specify how many bits of the block were actually data.
Padding the final block
Looking at the final block in a given message, it’s apparent that there are two pieces of data that could produce exactly the same output for a given function:
The original data, (which gets padded by the algorithm to make it 64 bytes), and
A modified version of the data, which has be modified by padding it in advance with the same bytes the algorithm would; this must then be followed by an
additional block
A “short” block with automatically-added padding produces the same output as a full-size block which has been pre-populated with the same data as the padding would
add.5In the case where we insert our own “fake” padding data, we can provide more message data after the padding and predict the overall hash. We can do this because
we the output of the first block will be the same as the final, valid hash we already saw. That known value becomes one of the two inputs into the function for the block that
follows it (the contents of that block will be the other input). Without knowing exactly what’s contained in the message – we don’t know the “secret key” used to salt it – we’re
still able to add some padding to the end of the message, followed by any data we like, and generate a valid hash.
Therefore, if we can manipulate the input of the message, and we know the length of the message, we can append to it. Bear that in mind as we move on to the other half
of what makes this attack possible.
Parameter overrides
“Images R Us” is implemented in PHP. In common with most server-side scripting languages,
when PHP sees a HTTP query string full of key/value pairs, if
a key is repeated then it overrides any earlier iterations of the same key.
Many online sources say that this “last variable matters” behaviour is a fundamental part of HTTP, but it’s not: you can
disprove is by examining $_SERVER['QUERY_STRING'] in PHP, where you’ll find the entire query string.
You could even implement your own query string handler that instead makes the first instance of each key the canonical one, if you really wanted.6It’d be tempting to simply override the download=free parameter in the query string at “Images R Us”, e.g. making it
download=free&download=valuable! But we can’t: not without breaking the hash, which is calculated based on the entire query string (minus the &key=...
bit).
But with our new knowledge about appending to the input for SHA-1 first a padding string, then an extra block containing our
payload (the variable we want to override and its new value), and then calculating a hash for this new block using the known output of the old final block as the
IV… we’ve got everything we need to put the attack together.
Putting it all together
We have a legitimate link with the query string download=free&key=ee1cce71179386ecd1f3784144c55bc5d763afcc. This tells us that somewhere on the server, this is
what’s happening:
I’ve drawn the secret key actual-size (and reflected this in the length at the bottom). In reality, you might not know this, and some trial-and-error might be necessary.7If we pre-pad the string download=free with some special characters to replicate the padding that would otherwise be added to this final8 block, we can add a second block containing
an overriding value of download, specifically &download=valuable. The first value of download=, which will be the word free followed by
a stack of garbage padding characters, will be discarded.
And we can calculate the hash for this new block, and therefore the entire string, by using the known output from the previous block, like this:
The URL will, of course, be pretty hideous with all of those special characters – which will require percent-encoding – on the end of the word ‘free’.
Doing it for real
Of course, you’re not going to want to do all this by hand! But an understanding of why it works is important to being able to execute it properly. In the wild, exploitable
implementations are rarely as tidy as this, and a solid comprehension of exactly what’s happening behind the scenes is far more-valuable than simply knowing which tool to run and what
options to pass.
That said: you’ll want to find a tool you can run and know what options to pass to it! There are plenty of choices, but I’ve bundled one called hash_extender into my example, which will do the job pretty nicely:
which algorithm to use (sha1), which can usually be derived from the hash length,
the existing data (download=free), so it can determine the length,
the length of the secret (16 bytes), which I’ve guessed but could brute-force,
the existing, valid signature (ee1cce71179386ecd1f3784144c55bc5d763afcc),
the data I’d like to append to the string (&download=valuable), and
the format I’d like the output in: I find html the most-useful generally, but it’s got some encoding quirks that you need to be aware of!
hash_extender outputs the new signature, which we can put into the key=... parameter, and the new string that replaces download=free, including
the necessary padding to push into the next block and your new payload that follows.
Unfortunately it does over-encode a little: it’s encoded all the& and = (as %26 and %3d respectively), which isn’t what we
wanted, so you need to convert them back. But eventually you end up with the URL:
http://localhost:8818/?download=free%80%00%00%00%00%00%00%00%00%00%00%00%00%00%00%00%00%00%00%00%00%00%00%00%00%00%00%00%00%00%00%00%00%00%e8&download=valuable&key=7b315dfdbebc98ebe696a5f62430070a1651631b.
Disclaimer: the image you get when you successfully exploit the test site might not actually be valuable.
And that’s how you can manipulate a hash-protected string without access to its salt (in some circumstances).
Mitigating the attack
The correct way to fix the problem is by using a HMAC in place
of a simple hash signature. Instead of calling sha1( SECRET_KEY . urldecode( $params ) ), the code should call hash_hmac( 'sha1', urldecode( $params ), SECRET_KEY
). HMACs are theoretically-immune to length extension attacks, so long as the output of the hash function used is
functionally-random9.
Ideally, it should also use hash_equals( $validDownloadKey, $_GET['key'] ) rather than ===, to mitigate the possibility of a timing attack. But that’s another story.
Footnotes
1 This attack isn’t SHA1-specific: it works just as well on many other popular hashing algorithms too.
2 SHA-1‘s blocks are 64 bytes
long; other algorithms vary.
3 For SHA-1, the padding bits
consist of a 1 followed by 0s, except the final 8-bytes are a big-endian number representing the length of the message.
4 SHA-1‘s IV is 67452301 EFCDAB89 98BADCFE 10325476 C3D2E1F0, which you’ll observe is little-endian counting from 0 to
F, then back from F to 0, then alternating between counting from 3 to 0 and C to F. It’s
considered good practice when developing a new cryptographic system to ensure that the hard-coded cryptographic primitives are simple, logical, independently-discoverable numbers like
simple sequences and well-known mathematical constants. This helps to prove that the inventor isn’t “hiding” something in there, e.g. a mathematical weakness that depends on a
specific primitive for which they alone (they hope!) have pre-calculated an exploit. If that sounds paranoid, it’s worth knowing that there’s plenty of evidence that various spy
agencies have deliberately done this, at various points: consider the widespread exposure of the BULLRUN programme and its likely influence on Dual EC DRBG.
5 The padding characters I’ve used aren’t accurate, just representative. But there’s the
right number of them!
6 You shouldn’t do this: you’ll cause yourself many headaches in the long run. But you
could.
7 It’s also not always obvious which inputs are included in hash generation and how
they’re manipulated: if you’re actually using this technique adversarily, be prepared to do a little experimentation.
8 In this example, the hash operates over a single block, but the exact same principle
applies regardless of the number of blocks.
9 Imagining the implementation of a nontrivial hashing algorithm, the predictability of
whose output makes their HMAC vulnerable to a length extension attack, is left as an exercise for the reader.
A particular joy of the Gemini and Spartan protocols – and the Markdown-like syntax of Gemtext – is their simplicity.
The best way to explore Geminispace is with a browser like Lagrange browser, of course.
Even without a browser, you can usually use everyday command-line tools that you might have installed already to access relatively human-readable content.
Here are a few different command-line options that should show you a copy of this blog post (made available via CapsulePress, of course):
Gemini
Gemini communicates over a TLS-encrypted channel (like HTTPS), so we need a to use a tool that speaks the language. Luckily: unless you’re on Windows you’ve probably got one installed
already1.
Using OpenSSL
This command takes the full gemini:// URL you’re looking for and the domain name it’s at. 1965 refers to the port number on
which Gemini typically runs –
GnuTLS closes the connection when STDIN closes, so we use cat to keep it open. Note inclusion of --no-ca-verification to allow self-signed
certificates (optionally add --tofu for trust-on-first-use support, per the spec).
Spartan is a little like “Gemini without TLS“, but it sports an even-more-lightweight request format which makes it especially
easy to fudge requests2.
Using Telnet
Note the use of cat to keep the connection open long enough to get a response, as we did for Gemini over GnuTLS.
Because TLS support isn’t needed, this also works perfectly well with Netcat – just substitute nc/netcat or whatever your platform calls it in place of
ncat:
Conveniently just-over-A5 sized, each of the two volumes is light enough to read in bed without uncomfortably clonking yourself in the face.
Set in the early-to-mid-1990s world in which the BBS is still alive and kicking, and the Internet’s gaining traction but still
lacks the “killer app” that will someday be the Web (which is still new and not widely-available), the story follows a handful of teenagers trying to find their place in the world.
Meeting one another in the 90s explosion of cyberspace, they find online communities that provide connections that they’re unable to make out in meatspace.
I loved some of the contemporary nerdy references, like the fact that each chapter page sports the “Geek Code” of the character upon which that chapter focusses.1So yeah: the whole thing feels like a trip back into the naivety of the online world of the last millenium, where small, disparate (and often local) communities flourished and
early netiquette found its feet. Reading Incredible Doom provides the same kind of nostalgia as, say, an afternoon spent on textfiles.com. But
it’s got more than that, too.
The user interfaces of IRC, Pine, ASCII-art-laden BBS menus etc. are all produced with
a good eye for accuracy, but don’t be fooled: this is a story about humans, not computers. My 9-year-old loved it too, and she’s never even heard of IRC (I hope!).
It touches on experiences of 90s cyberspace that, for many of us, were very definitely real. And while my online “scene” at around the time that the story is set might have been
different from that of the protagonists, there’s enough of an overlap that it felt startlingly real and believable. The online world in which I – like the characters in the story – hung
out… but which occupied a strange limbo-space: both anonymous and separate from the real world but also interpersonal and authentic; a frontier in which we were still working out the
rules but within which we still found common bonds and ideals.
Having had times in the 90s that I met up offline with relative strangers whom I first met online, I can confirm that… yeah, the fear is real!
Anyway, this is all a long-winded way of saying that Incredible Doom is a lot of fun and if it sounds like your cup of tea, you should read it.
Also: shortly after putting the second volume down, I ended up updating my Geek Code for the first time in… ooh, well over a decade. The standards have moved on a little (not entirely
in a good way, I feel; also they’ve diverged somewhat), but here’s my attempt:
----- BEGIN GEEK CODE VERSION 6.0 -----
GCS^$/SS^/FS^>AT A++ B+:+:_:+:_ C-(--) D:+ CM+++ MW+++>++
ULD++ MC+ LRu+>++/js+/php+/sql+/bash/go/j/P/py-/!vb PGP++
G:Dan-Q E H+ PS++ PE++ TBG/FF+/RM+ RPG++ BK+>++ K!D/X+ R@ he/him!
----- END GEEK CODE VERSION 6.0 -----
Footnotes
1 I was amazed to discover that I could still remember most of my Geek Code
syntax and only had to look up a few components to refresh my memory.
My second day of the main conference part of WordCamp Europe 2023 was hampered slightly by a late start on my part.
I can’t say for certain why I woke up mildly hungover and with sore knees, but I make an educated guess that it might be related to the Pride party I found myself at last night.
Still, I managed to get to all the things I’d earmarked for my attention, including:
I’m sure I can’t be the only person who’s been asked “why can’t the (or ‘shouldn’t the’) WordPress post editor let multiple people edit post at the same time”. Often, people
will compare it to e.g. Google Docs.
I can’t begin to speculate how often people must ask this supposedly-trivial question of Dawid Urbański, possibly the world’s expert on this
very question.
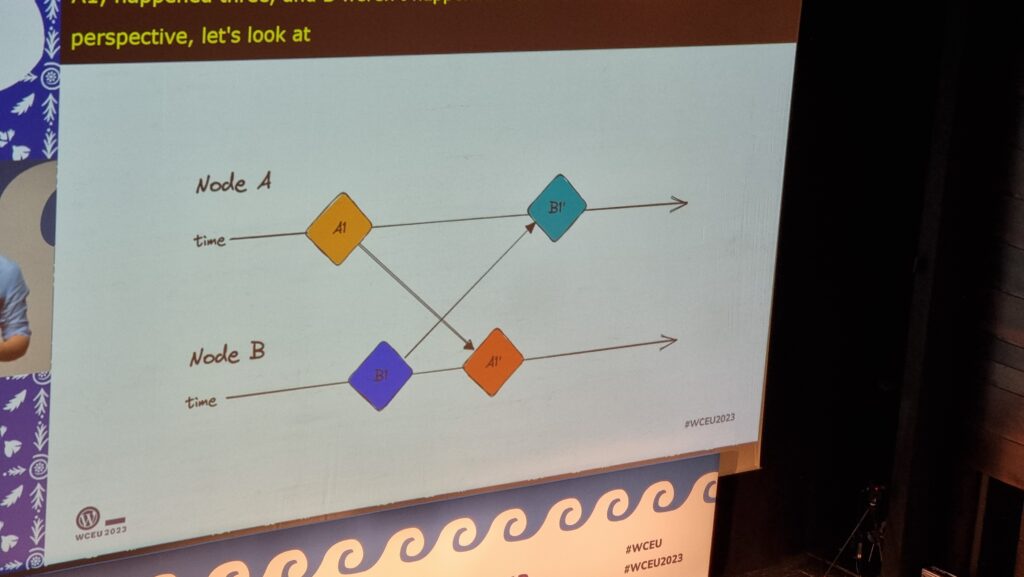
Dawid summarised the challenging issues in any effort to implement this much-desired feature. Some of them are examples of those unsolved problems that keep rearing their heads in
computer science, like the two generals’ problem, but even the solvable problems are difficult: How does one
handle asynchronous (non-idempotent) commutative operations? How is the order of disparate actions determined? Which node is the source of truth? If a server is used, where is that
server (with a nod to quite how awful the experience of implementing a Websockets server in PHP can be…)? And so on…
Slides showing simplified timelines of parties communicating with one another in ambigous ways
I really appreciated Dawid’s reference to the various bits of academic literature that’s appeared over the last four decades (!) about how these problems might be solved. It’s a strong
reminder that these things we take for granted in live-updating multi-user web applications are not trivial and every question you can answer raises more questions.
There’s some great early proof-of-concepts, so we’re “getting there”, and it’s an exciting time. Personally, I love the idea of the benefits this could provide for offline editing
(perhaps just because I’m still a huge fan of a well-made PWA!).
James Giroux’s goal: that we all become more curious about and more invested in our team’s experiences, from a humanistic standpoint. His experience of companies with organic growth of
software companies is very, very familiar: you make a thing and give it away, then you need more people, then you’ve somehow got a company and it’s all because you just had an idea
once. Sounds like Three Rings!
Financial success is not team success, as Twitter shows, with their current unsustainable and unhappy developer culture, James reminds us.
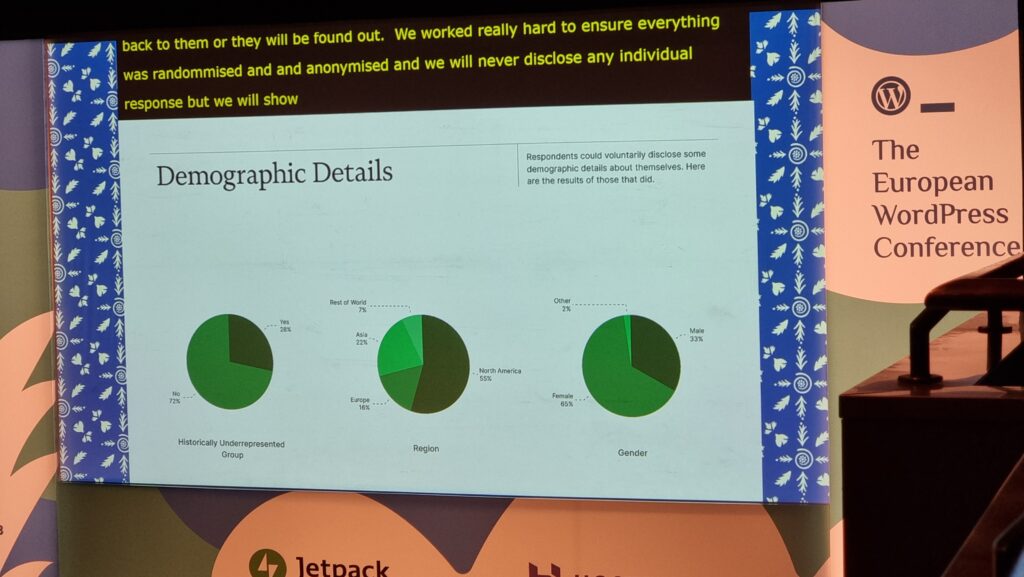
James was particularly keen to share with us the results of his Team Experience Index research, and I agree that some of the result are
especially exciting, in particularly the willingness of underrepresented groups, especially women, to enagage with the survey: this provides hugely valuable data about the health of
teams working in the WordPress space.
The statistician in me immediately wanted to know how the non-response rate to these (optional) questions varied relative to one another (if they’re very different, putting these pie
charts alongside one another could be disingenuous!), but I’m tentatively excited by the diversity represented anyway.
“We have this project that we work with and contribute to, that we love,” says James, in an attempt to explain the highly-positive feedback that his survey respondents gave when asked
questions about the authenticity of their purpose and satisfaction in their role.
Again, my inner statistician wants to chirp up about the lack of a control group. The data from the survey may well help companies working within the WordPress ecosystem to
identify things we’re doing well and opportunities for growth, but it’d also be cool to compare these metrics to those in companies outside of the WordPress world!
So, what do we do with these findings? How do WordPress-ey companies improve? James recommends that we:
Get better are showing what recognition, celebration, and career growth looks like,
Improve support and training for team leaders to provide them with the tools to succeed and inspire, and
Bridge the gap between leadership and team members with transparent, open dialogue.
Good tips, there.
The Big Photo
A WordCamp tradition is to try to squeeze every willing participant into a photo. Clearly with the size that these events are, nowadays, this requires some wrangling (and, in this case,
the photographers standing atop the roof of a nearby building to get everybody into frame).
Like herding cats, trying to get several hundred people to line up where you want them for a photograph is an exercise in patience.
I’ll have to keep an eye out for the final picture and see if I can find myself in it.
I always find that learning about bleeding edge CSS techniques makes me feel excited and optimistic, perhaps because
CSS lends itself so well towards a progressive enhancement approach to development: often, you can start using a new technique
today and it’ll only benefit, say, people using a beta version of a particular browser (and perhaps only if they opt-in to the applicable feature flag). But if you’ve designed
your site right then the lack of this feature won’t impact anybody else, and eventually the feature will (hopefully) trickle-down into almost everybody’s Web experience.
Anyway, that’s what Fellyph Cintra says too, but he adds that possibly we’ve still not grown out of thinking that browsers take a long
time between versions. 5 years passed between the release of Internet Explorer 6 and Internet Explorer 7, for example! But nowadays most browsers are evergreen with releases each
month! (Assuming we quietly ignore that Apple don’t sent new versions of Safari to old verisons of MacOS, continuing to exacerbate a problem that we used to see with Internet Explorer
on Windows, ahem.)
Fellyph told us about how he introduced <dialog> to his team and they responded with skepticism that they’d be able to use it within the next 5 years. But in fact
it’s already stable in every major browser.
An important new development may come from Baseline, a project to establish a metric of what you can reliably use on the Web today. So a
bit like Can I Use, I guess, but taken from the opposite direction: starting from the browsers and listing the features, rather than the other way
around.
Anyway, Fellyph went on to share some exciting new ideas that we should be using, like:
object-fit and object-position, which can make the contents of any container “act like” a background
aspect-ratio, which I’m already using and I love, but I enjoyed how Fellyph suggested combining the two to crop images to a fluid container on the client side
scroll-behavior: smooth, which I’ve used before; it’s pretty good
clamp, which I use… but I’m still not sure I fully grok it: I always have to load some documentation with examples when I use it
@container queries, which can apply e.g. (max-width: ...) rules to things other than the viewport, which I’ve not found a need for yet but I can see the
value of it
@layers, which grant an additional level of importance in the cascade: for example, you might load a framework into a layer (with @import url(...)
layer(framework)) which is defined as a lower-priority than your override layer, meaning you won’t have to start slapping !important all over the shop
@media (400px <= width <= 600px)-style media queries, which are much easier to understand than min-width: if you’re used to thinking in a
more-procedural programming language (I assume they work in container queries too!)
…
It’s also worth remembering:
@supports, which is badass and I love and use it already (it was especially useful as display: grid began to roll out and I wanted to start using it but
needed to use a fallback method for browsers that didn’t support it yet
:has(), which I’ve long thought is game-changing: styling something based on what it contains is magical; not really suitable for mainstream use yet without
Firefox support, though (it’s still behind a feature flag)! Fellyph sold me on the benefit of :not(:has(...)), though!
Nesting, which again doesn’t have Firefox support yet but provides SCSS-like nesting in CSS, which is awesome
Scroll-driven animations, which can e.g. do parallax effects without JavaScript (right now it’s Canary only, mind…), using e.g. animation-timeline: and
animation-range: to specify that it’s the scroll position within the document that provides the timeline for the animation
And keeping an eye on upcoming things like text-balanced (which I’m already excited by), popover, selectmenu, view transitions (which I’ve been
experimenting with because they’re cool), and scoped style.
For my second workshop, I joined Google’s Adam Silverstein to watch him dissect a few participants’ websites performance using Core Web
Vitals as a metric. I think I already know the basics of Core Web Vitals, but when it comes to improving my score (especially on work-related sites with
unpleasant reliance on heavyweight frameworks like React, in my experience).
In an early joke, Adam pointed out that you can reduce JavaScript thread blocking by removing JavaScript from your site. A lot of people laughed, but frankly I think it’s a great
idea.
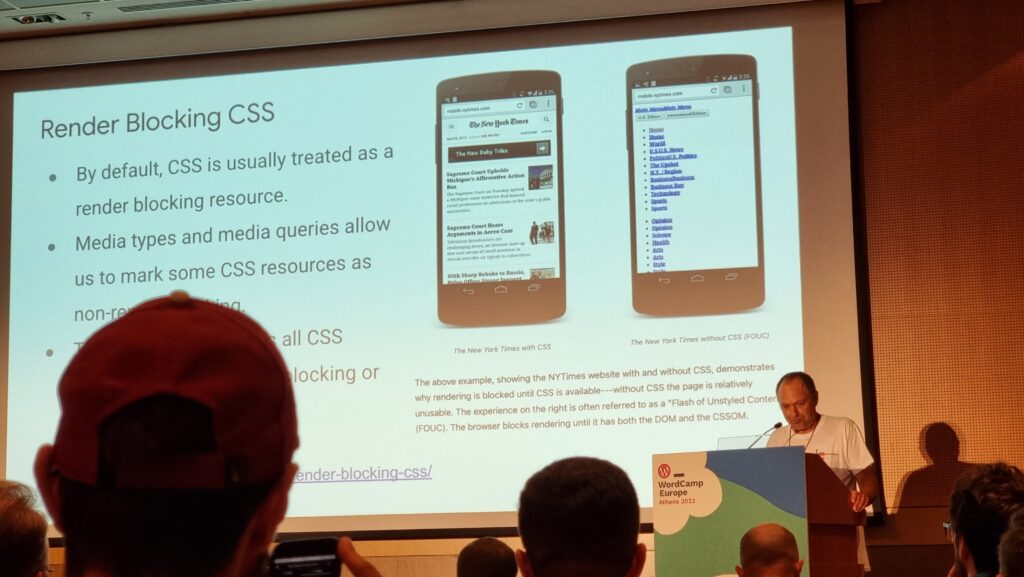
We talked a lot about render blocking (thanks to JS and CSS in the
<head>), thread blocking (by scripts, especially those reacting to user input), TTFB (relating to actual network
and server performance, or at least server-side processing), TBT (the time between FCP and TTI), and the upcoming change to measure INP rather than FID. That’s a lot of acronyms.
The short of it is that there are three pillars to Core Web Vitals: loading (how long until the page renders), interactivity (how long until the page
responds to user interaction), and stability (how long it takes for the page to cease layout shifts as a result of post-load scripts and stylesheets). I was pleased
that Adam acknowledged the major limitation of lab testing resulting from developers often using superior hardware and Internet connections to typical users, and how if you’re
serious about performance metrics you’ll want to collect RUM data.
The fastest way to improve rendering performance is to put fewer obstacles in the way of rendering.
I came away with a few personalised tips, but they’re not much use for your site: I paid attention to the things that’ll be helpful for the sites I look after. But
I’ll be taking note of his test pages so I can play with some of the tools he demonstrated later on.
I couldn’t liveblog this because I spent too much of the session applauding. A few highlights from memory:
Phase 2 (of 4) of Gutenberg is basically complete, which is cool. Some back-and-forth about the importance of phase 4 (bringing better multilingual support to WordPress) and how it
feels like it’s a long way away.
In the same vein as his 2016 statement that WordPress developers should “learn JavaScript deeply”, Matt leant somewhat into the idea that from today they
should “watch AI carefully”; I’m not 100% convinced, but it’s not been stopping me from getting involved with a diversity of AI experiments (including some WordPress-related ones)
anyway.
Musings about our community being a major part of why WordPress succeeded (and continues to thrive) unlike some other open source projects of its era. I agree that’s a
factor, but I suspect that being in the right place at the right time was also important. Perhaps more on that another time.
Announcement of the next WordCamp Europe location.
This post is basically a live-blog of everything I got up to, and it’s mostly for my own benefit/notetaking. If you don’t read it, nobody will blame you.
Six minutes after workshop registration opened its queue snaked throughout an entire floor of the conference centre.
David Artiss took the courageous step of installing 36 popular plugins onto a fresh WordPress site and was, unsurprisingly, immediately bombarded by a
billion banners on his dashboard. Some were merely unhelpful (“don’t forget to add your API key”), others were annoying (“thanks for installing our plugin”), and plenty more were
commercial advertisements (“get the premium version”) despite the fact that WordPress.org guidelines recommend against this. It’s no surprise that this kind of “aggressive promotion” is
the single biggest annoyance that people reported when David asked around on social media.
Similarly, plugins which attempt to break the standard WordPress look-and-feel by e.g. hoisting themselves to the top of the menu, showing admin popovers, putting settings sections in
places other than the settings submenu, and so on are a huge annoyance to everybody. I get sufficiently frustrated by these common antifeatures of plugins I use that I actually maintain
a plugin for my own use that “fixes” the ones that aggrivate me the most!
David raised lots of other common gripes with WordPress plugins, too: data validation failures, leaving content behind after uninstallation (and “deactivation surveys”, ugh!), and a
failure to account for accessibility.
I’m unconvinced that we can rely on plugin developers to independently fix the kinds of problems that come high on David’s list. I wonder if there’s mileage in WordPress Core
reimplementing the way that the main navigation menu works such that all items in it can be (easily) re-arranged by users to their own preference? This would undermine the perceived
value to plugin developers of “hoisting” their own to the top by allowing users to counteract it, and would provide a valuable feature to allow site admins to streamline their workflow:
use WooCommerce but only in a way that’s secondary to your blog? Move “Products” below “Posts”! Etc.
Why yes, I’m liveblogging this. And yes, I’m not using Gutenberg yet (that’s a whole other story…)
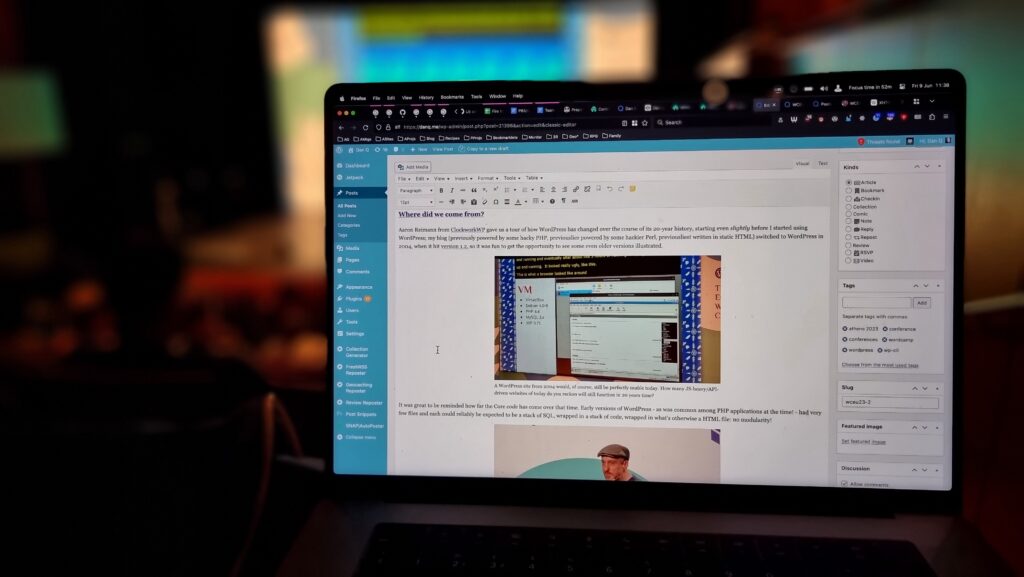
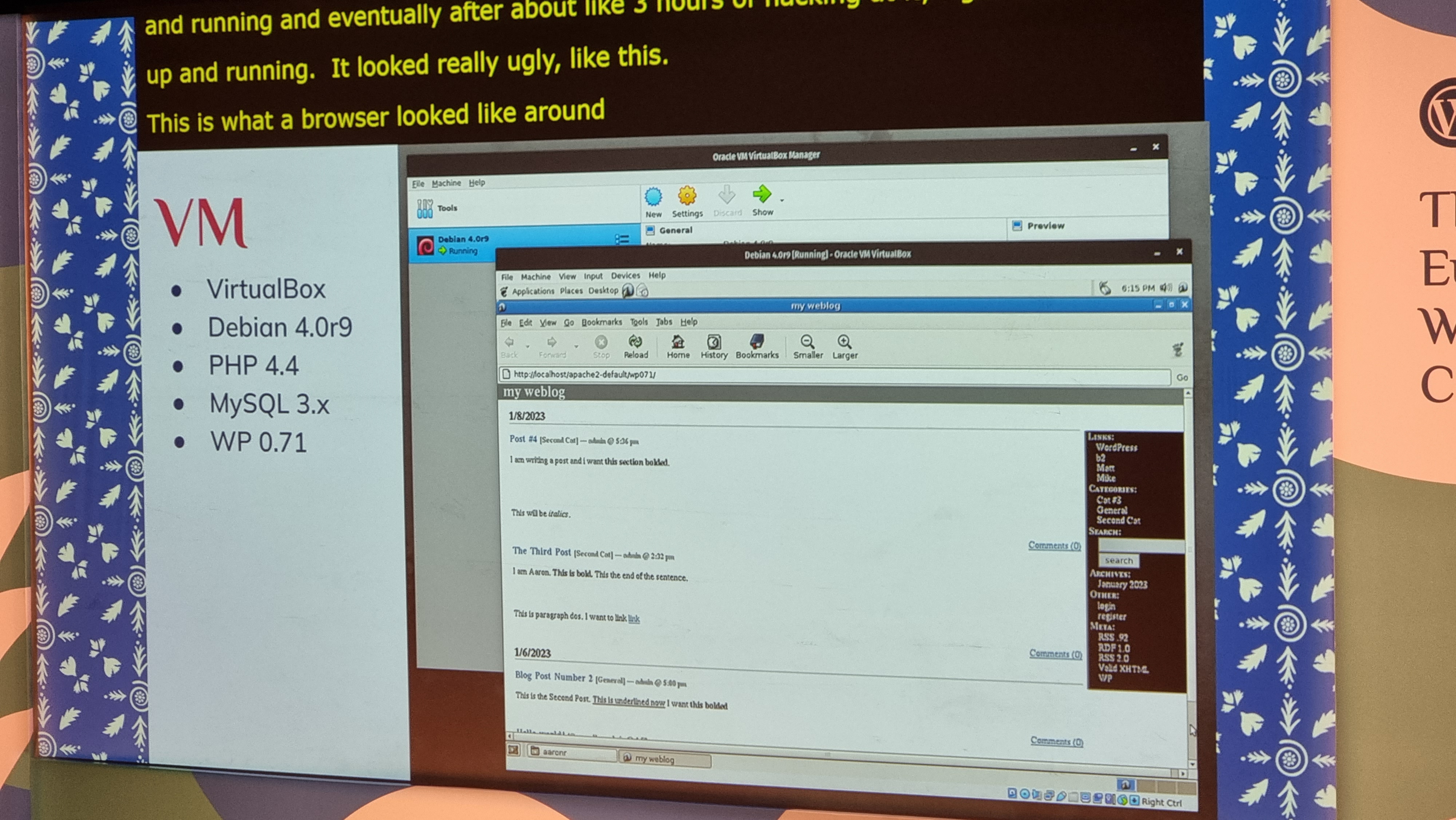
Aaron Reimann from ClockworkWP gave us a tour of how WordPress has changed over the course of its 20-year history, starting even slightly
before I started using WordPress; my blog (previously powered by some hacky PHP, previouslier powered by some hackier Perl, previousliest written in static HTML) switched to WordPress
in 2004, when it hit version 1.2, so it was fun to get the opportunity to see some even older versions
illustrated.
A WordPress site from 2004 would, of course, still be perfectly usable today. How many JS-heavy/API-driven websites of today do you reckon will still function in 20 years time?
It was great to be reminded how far the Core code has come over that time. Early versions of WordPress – as was common among PHP applications at the time! – had very few files
and each could reliably be expected to be a stack of SQL, wrapped in a stack of code, wrapped in what’s otherwise a HTML file: no modularity!
Aaron’s passion for this kind of digital archaeology really shows. I dig it.
There were very few surprises for me in this talk, as you might expect for such an “old hand”, but I really enjoyed the nostalgia of exploring WordPress history through his eyes.
I enjoyed putting him on the spot with a “spicy” question at the end of his talk, by asking him if, alongside everything we’ve gained over the years, whether there’s anything we
lost along the way. He answered well, pointing out that the somewhat bloated stack of plugins that are commonplace on big sites nowadays and the ease with which admins can just
“click and install” more of them. I agree with him, although personally I miss built-in XFN support…
If you’d have told me in advance that hugging a Wapuu would have been a highlight of the day… yeah, that wouldn’t have been a surprise!
Networking And All That
There’s a lot of exhibitors with stands, but I tried to do a circuit or so and pay attention at least to those whose owners I’ve come into contact with in a professional
capacity. Many developers who make extensions for WooCommerce, of course, sell those extensions through WooCommerce.com, which means they come
into routine direct contact with my code (and it can mean that when their extension’s been initially rejected by our security scanners or linters, it’s me their developers first want to
curse!).
After a while, to spare some of that awkward exchange where somebody tries to sell me their product before I explain that I already sell their product for them, I slapped a
“Woo” sticker on my lanyard.
It’s been great to connect with people using WordPress to power the Web in a whole variety of different contexts, but it somehow still feels strange to me that WordPress has such a
commercial following! Even speaking as somebody who’s made their living at least partially out of WordPress for the last decade plus, it still feels to me like its greatest
value comes from its use for personal publishing.
The feel of a WordCamp with its big shiny sponsors is enormously different from, say, the intimacy and individuality of a Homebrew Website
Club meeting, and I think that’s something I still need to come to terms with. WordPress’s success story comes from many different causes, but perhaps chief among them is the fact
that it’s versatile enough to power the website of a government, multinational, or household-name brand… but also to run the smallest personal indie blog. I struggle to comprehend that,
even with my background.
My division of Automattic had a presence, of course.
I was proud of my colleagues for the “gimmick” they were using to attract people to the Woo stand: you could pick up a “credit card” and use it to make a purchase (of Greek olive oil)
using a website, see your order appear on the app at the backend in real-time, and then receive your purchase as a giveaway. The “credit
card” doubles as a business card from the stand, the olive oil is a real product from a real, local producer (who really uses WooCommerce to sell online!), and when you provide an email
address at the checkout you can opt-in to being contacted by the team afterwards. That’s some good joined-up thinking by my buddies in marketing!
Petya Petkova observed that it’s commonplace to take the easy approach and make a website look like… well, every other website. “Web
deja-vu” is a real thing, and it’s fed not only by the ebbs and flows of trends in web design but by the proliferation of indistinct themes that people just install-and-use.
How can we break free from web deja-vu, asks Petya. It almost makes me sad that her slides had been coalesced into the conference’s slidedeck design rather than being her own…
although on second though maybe that just helps enhance the point!
Choice of colours and typography can be used to tell a story, to instil a feeling, to encourage engagement. Scrolling can be used as a metaphor for storytelling (“scrolly-telling”,
Petya calls it). Animation flow can be used to direct a user’s attention and drive focus and encourage interaction.
A lot of the technical concepts she demonstrated – parts of a page that scroll at different speeds, typography that shifts or changes, videos used in a subtle way to accentuate other
content, etc. – can be implemented in the frontend with WebGL, Three.js and the like. Petya observes that moving this kind of content interactivity into the frontend can produce an
illusion of a performance improvement, which is an argument I’ve heard before, but personally I think it’s only valuable if it’s built as a progressive enhancement: otherwise, you’re
always at risk that your site won’t look like you’d hope.
I note, for example, that Petya’s agency’s site shows only an “endless spinner” when viewed in my browser (which blocks the code.jQuery CDN by
default, unless allowlisted for specific sites). All of the content is there, on the page, if you View Source, but it’s completely invisible if an external JavaScript fails to
load. That doesn’t just happen when weirdos like me disable JavaScript in their browsers: it can happen if the browser interacts badly with the script, or if the user’s Internet
connection is ropey, or a malware scanner misfires, or if government censorship blocks the CDN, or in any number of other conditions.
While I agree with Petya about the value of animation and interactivity to make sites awesome, I don’t think it can take second-place to ensuring the most-widespread access and
accessibility for your audience. Otherwise we’d still be making Flash sites, right?
So yeah: uniqueness and creativity are great, and I like what she’s proposing, but not the way she goes about it. The first person to ask a question wisely brought up accessibility, and
Petya answered well that accessibility technologies can bridge the gap, but I’d counter that it’s preferable to build accessible in the first instance: if you have to
use an aria- attribute it’s a good sign that you probably already did something wrong (not always, but it’s certainly a pointer that you ought to take a step back
and check!).
Several other good questions and great answers followed: about how to showcase a preliminary design when they design is dependent upon animation and interactivity (which I’ve witnessed
before!), on the value of server-side rendering of components, and about how to optimise for smaller screens. Petya clearly knows her stuff in all of these areas and had confident
responses.
Oliver Sild is the kind of self-taught hacker, security nerd, and community builder that I love, so I wasn’t going to miss his talk.
The number of security vulnerability reports in the WordPress ecosystem is up +328%, Oliver opened. But the bugs being reported are increasingly old, so we’re not talking
about new issues being created. And only 0.3% of bugs were in WordPress Core (and were patched before they were exploitable).
It’s good news in general in WordPress Security-land… but CSRF is on the up-and-up (overtaking XSS) in the plugin space. That, and all the broken access control we see in the admin area, are things I’ll be keeping in mind next time I’m arguing
with a vendor about the importance of using nonces and security checks in their extension (I have this battle from time to time!).
But an interesting development is the growth of the supply chains in the WordPress plugin ecosystem. Nowadays a plugin might depend upon another plugin which might depend upon a
library… and a patch applied to the latter of those might take time to be propagated through the chain, providing attackers with a growing window of opportunity.
I love a good Sankey chart. Even when it says scary things.
A worrying thought is that while plugin directory administrators will pull and remove plugins that have longstanding unactioned security issues. But that doesn’t help the sites that
already have that plugin installed and are still using it! There’s a proposal to allow WordPress to notify admins if a plugin
used on a site has been dropped for security reasons, but it was opened 9 years ago and hasn’t seen any real movement, soo…
I like that Oliver plugged for security researchers being acknowledged as equal contributors to developers on your software. But then, I would say that, as somebody who breaks into
things once in a while and then tells the affected parties how to fix the problem that allowed me to do so! He also provided a whole wealth of tips for site owners and agencies to try
to keep their sites safe, but little that I wasn’t aware of already.
Still, good to see this talk get as good an audience as it did, given the importance of the topic!
It was about this point in the day, glancing at my schedule and realising that at any given time there were up to four other sessions running simultaneously, that I really got
a feel for the scale of this conference. Awesome. Meanwhile, Oliver was fielding the question that I’m sure everybody was thinking: with Gutenberg blocks powered by JavaScript that are
often backed by a supply-chain of the usual billion-or-so files you find in your .node_modules directory, isn’t the risk of supply chain attacks increasing?
Spoiler: yes. Did you notice earlier in this post I mentioned that I don’t use Gutenberg on this site yet?
When the Jetpack team told me that they’ve been improving their cloud offering, this wasn’t what I expected.
My first “workshop” was run by Giulia Laco, on the topic of readable content and design.
Designers to the left of me, coders to the right: here I am, stuck in the middle with you.
Giulia began by reminding us how short the attention span of Web readers is, and how important the right typographic choices are in ensuring that people actually read your content. I
fully get this – I think that very few people will have the attention span to read this part of this very blog post, for example! – but I loved that she hammered the point home
by presenting every slide of her presentation twice (or more), “improving” the typographic choices as she went along: an excellent and memorable quirk.
Our capacity to read and comprehend a text is affected by a combination of common (distance, lighting, environment, concentration, mood, etc.), personal (age, proficiency, motiviation,
accessibility requirements, etc.), and typographic (face, style, size, line length and spacing, contrast, width, rhythm etc.) factors. To explore the impact of the typographic factors,
the group dived into a pre-prepared Codepen and a shared Figma diagram. (I immediately had a TIL moment over the font-synthesis: CSS property!)
I appreciated that Giulia stressed the importance of a fallback font. Just like the CDN issues I described above while talking about JavaScript dependencies, not specifying a fallback
font puts your design at the mercy of the browser’s defaults. We don’t like to think about what happens when websites partially fail, but they do, and we should.
Things get interesting at the intersection of readability and accessibility. For example, WCAG accessibility requirements demand that you don’t use images of text (we used to
do this a lot back before we could reliably use fonts on the web, and before we could easily have background images on e.g. buttons for navigation). But this accessibility
requirement also aids screen readability when accounting for e.g. “retina” screens with virtual pixel ratios.
Do you remember when a pixel was the size of a pixel? Those days are long gone. True story.
Giulia provided a great explanation of why we may well think in pixels (as developers or digital designers) but we’re unlikely to use them everywhere: I’d internalised
this lesson long ago but I appreciated a well-explained justification. The short of it is: screen zoom (that fancy zoom feature you use in your browser all the time, especially on
mobile) and text zoom (the one you probably don’t use, or don’t use so much) are different things, and setting a pixel-based font size in the root node wrecks the latter, forcing some
people with accessibility needs to use the former, which is likely to result in vertical scrolling. Boo!
I also enjoyed seeing this demo of how the different hyphenation-points in different languages (because of syllable stress) can impact on
your wrapping points/line lengths when content is translated. This can affect any website, of course, because any website can be the target of automatic translation.
Plus, Giulia’s thoughts on the value of serifed fonts (even on digital displays) for improving typographic readability of the letters d, b, p and q which are often mirror- or
rotationally-symmetric to one another in sans-serif fonts. It’s amazing to have something – in this case, a psychological letter transposition – pointed out that I’ve experienced but
never pinned down the reason for, before. Neat!
It was a shame that this workshop took place late in the day, because many of the participants (including me) seemed to have flagging energy levels!
Altogether a great (but intense) day. Boggles my mind that there’s another one like it tomorrow.
103: Early Hints (“I’m not sure this can last forever.”)
300: Multiple Choices (“There are so many ways I can do better than you.”)
303: See Other (“You should date other people.”)
304: Not Modified (“With you, I feel like I’m stagnating.”)
402: Payment Required (“I am a prostitute.”)
403: Forbidden (“You don’t get this any more.”)
406: Not Acceptable (“I could never introduce you to my parents.”)
408: Request Timeout (“You keep saying you’ll propose but you never do.”)
409: Conflict (“We hate each other.”)
410: Gone (ghosted)
411: Length Required (“Your penis is too small.”)
413: Payload Too Large (“Your penis is too big.”)
416: Range Not Satisfied (“Our sex life is boring and repretitive.”)
425: Too Early (“Your premature ejaculation is a problem.”)
428: Precondition Failed (“You’re still sleeping with your ex-!?”)
429: Too Many Requests (“You’re so demanding!”)
451: Unavailable for Legal Reasons (“I’m married to somebody else.”)
502: Bad Gateway (“Your pussy is awful.”)
508: Loop Detected (“We just keep fighting.”)
With thanks to Ruth for the conversation that inspired these pictures, and apologies to the rest of the Internet for creating them.
On Wednesday this week, three years and two months after Oxford Geek Nights #51, Oxford Geek Night
#52. Originally scheduled for 15 April 2020 and then… postponed slightly because of the pandemic, its reapparance was an epic moment that I’m glad to have been a part of.
A particular highlight of the night was witnessing “Gasman”Matt Westcott show off his
epic demoscene contribution Pharmageddon, which is presented via a “pharmacy sign”. Here’s a video, if you’re interested.
Ben Foxall also put in a sterling performance; hearing him talk – as usual – made me say “wow, I didn’t know you could do that with a
web browser”. And there was more to learn, too: Jake Howard showed us how robots see, Steve Buckley inspired us to think about how technology can make our homes more energy-smart (this is really cool and sent me
down a rabbithole of reading!), and Joe Wass showed adorable pictures of his kid exploring the user interface of his lockdown electronics
project.
Oh, and there was a quiz competition too, and guess who came out on top after an incredibly tight race.
But mostly I just loved the chance to hang out with geeks again; chat to folks, make connections, and enjoy that special Oxford Geek Nights atmosphere. Also great to meet somebody from
Perspectum, who look like they’d be great to work for and – after hearing about – I had in mind somebody to suggest for a job with them… but it
looks like the company isn’t looking for anybody with their particular skills on this side of the pond. Still, one to watch.
My prize for winning the competition was an extremely-limited-edition cap which I love so much I’ve barely taken it off since.
Huge thanks are due to Torchbox, Perspectum and everybody in attendance for making this magical night possible!
Oh, and for anybody who’s interested, I’ve proposed to be a speaker at the next Oxford Geek Nights, which sounds like it’ll be towards Spring 2023. My title is
“Yesterday’s Internet, Today!” which – spoilers! – might have something to do with the kind of technology I’ve been playing with recently, among other things. Hope to see you there!
Different games in the same style (absurdle plays adversarially like my cheating hangman
game, crosswordle involves reverse-engineering a wordle colour grid into a crossword, heardle
is like Wordle but sounding out words using the IPA…)
I’m sure that by now all your social feeds are full of people playing Wordle. But the cool nerds are playing something new…
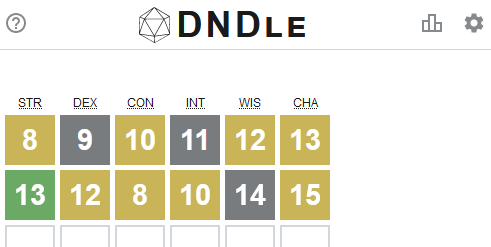
Now, a Wordle clone for D&D players!
But you know what hasn’t been seen before today? A Wordle clone where you have to guess a creature from the Dungeons & Dragons (5e) Monster Manual by putting numeric values into a
character sheet (STR, DEX, CON, INT, WIS, CHA):
Just because nobody’s asking for a game doesn’t mean you shouldn’t make it anyway.
What are you waiting for: go give DNDle a try (I pronounce it “dindle”, but you can pronounce it however you like). A new monster
appears at 10:00 UTC each day.
And because it’s me, of course it’s open source and works offline.
The boring techy bit
Like Wordle, everything happens in your browser: this is a “backendless” web application.
I’ve used ReefJS for state management, because I wanted something I could throw together quickly but I didn’t want to drown myself (or my players)
in a heavyweight monster library. If you’ve not used Reef before, you should give it a go: it’s basically like React but a tenth of the footprint.
A cache-first/background-updating service worker means that it can run completely offline: you can install it to your homescreen in the
same way as Wordle, but once you’ve visited it once it can work indefinitely even if you never go online again.
I don’t like to use a buildchain that’s any more-complicated than is absolutely necessary, so the only development dependency is rollup. It
resolves my import statements and bundles a single JS file for the browser.
As you might know if you were paying close attention in Summer 2019, I run a “URL
shortener” for my personal use. You may be familiar with public URL shorteners like TinyURL
and Bit.ly: my personal URL shortener is basically the same thing, except that only
I am able to make short-links with it. Compared to public ones, this means I’ve got a larger corpus of especially-short (e.g. 2/3 letter) codes available for my personal use. It also
means that I’m not dependent on the goodwill of a free siloed service and I can add exactly the features I want to it.
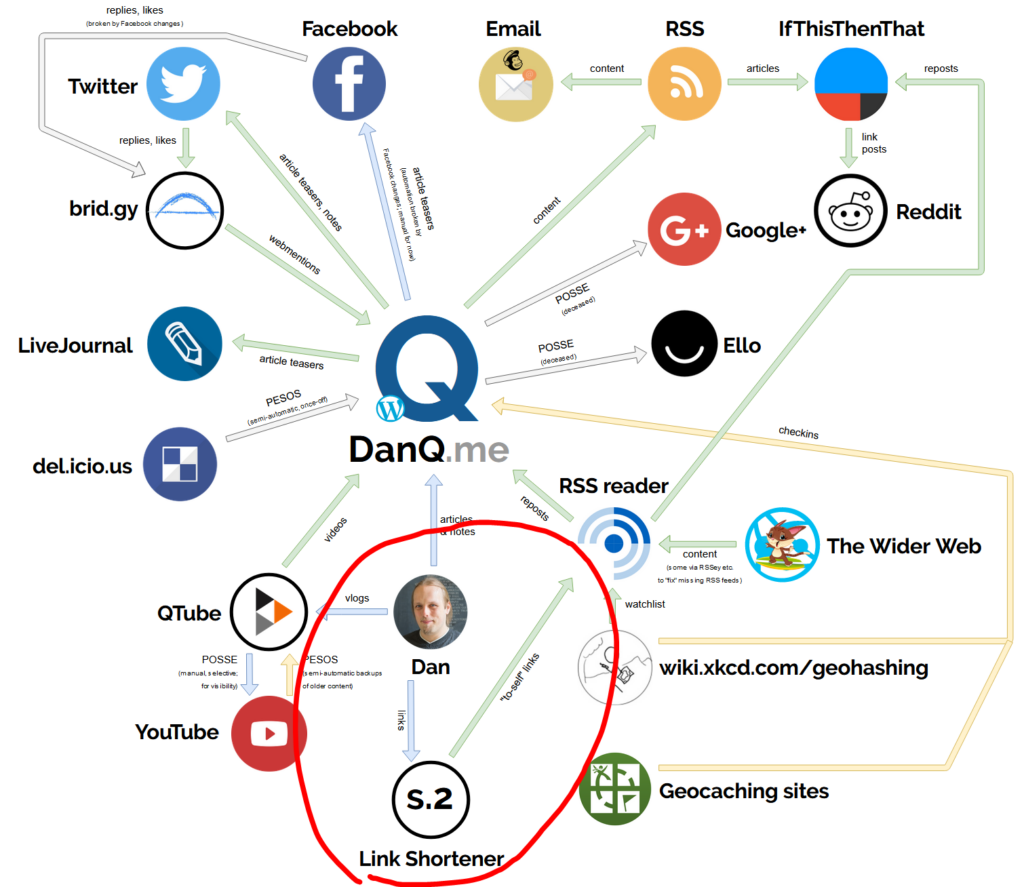
Little wonder then that my link shortener sat so close to me on my ecosystem diagram the other year.
For the last nine years my link shortener has been S.2, a tool I threw together in Ruby. It stores URLs in a
sequentially-numbered database table and then uses the Base62-encoding of the primary key as the “code” part of the short URL. Aside from the fact that when I create a short link it shows me a QR code to I can
easily “push” a page to my phone, it doesn’t really have any “special” features. It replaced S.1, from which it primarily differed by putting the code at the end of the URL rather than as part of the domain name, e.g. s.danq.me/a0 rather than a0.s.danq.me: I made the switch
because S.1 made HTTPS a real pain as well as only supporting Base36 (owing to the case-insensitivity of domain names).
But S.2’s gotten a little long in the tooth and as I’ve gotten busier/lazier, I’ve leant into using or adapting open source tools more-often than writing my own from scratch. So this
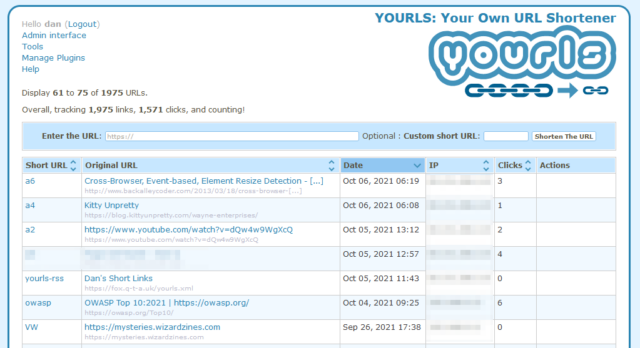
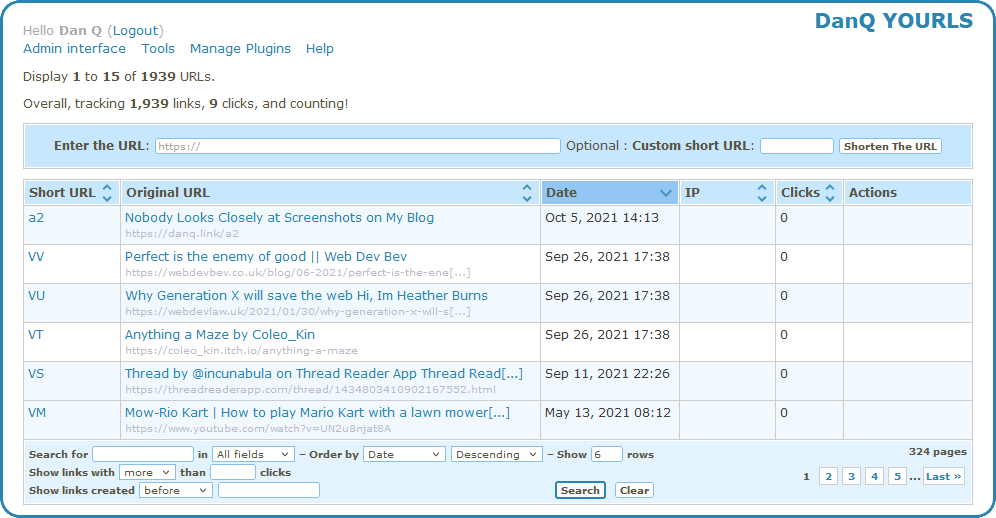
week I switched my URL shortener from S.2 to YOURLS.
YOURLs isn’t the prettiest tool in the world, but then it doesn’t have to be: only I ever see the interface pictured above!
One of the things that attracted to me to YOURLS was that it had a ready-to-go Docker image. I’m not the biggest fan of Docker in general,
but I do love the convenience of being able to deploy applications super-quickly to my household NAS. This makes installing and maintaining my personal URL shortener much easier than it
used to be (and it was pretty easy before!).
Another thing I liked about YOURLS is that it, like S.2, uses Base62 encoding. This meant that migrating my links from S.2 into YOURLS could be done with a simple cross-database
INSERT... SELECT statement:
One of S.1/S.2’s features was that it exposed an RSS feed at a secret URL for my reader to ingest. This was great, because it meant I could “push” something to my RSS reader to read or repost to my blog later. YOURLS doesn’t have such a feature, and I couldn’t find anything in the (extensive) list of plugins that would do it for me. I needed to write my own.
In some ways, subscribing “to yourself” is a strange thing to do. In other ways… shut up, I’ll do what I like.
I could have written a YOURLS plugin. Or I could have written a stack of code in Ruby, PHP, Javascript or
some other language to bridge these systems. But as I switched over my shortlink subdomain s.danq.me to its new home at danq.link, another idea came to me. I
have direct database access to YOURLS (and the table schema is super simple) and the command-line MariaDB client can output XML… could I simply write an XML
Transformation to convert database output directly into a valid RSS feed? Let’s give it a go!
I wrote a script like this and put it in my crontab:
mysql --xml yourls -e \"SELECT keyword, url, title, DATE_FORMAT(timestamp, '%a, %d %b %Y %T') AS pubdate FROM yourls_url ORDER BY timestamp DESC LIMIT 30"\
| xsltproc template.xslt - \
| xmllint --format - \
> output.rss.xml
The first part of that command connects to the yourls database, sets the output format to XML, and executes an
SQL statement to extract the most-recent 30 shortlinks. The DATE_FORMAT function is used to mould the datetime into
something approximating the RFC-822 standard for datetimes as required by
RSS. The output produced looks something like this:
<?xml version="1.0"?><resultsetstatement="SELECT keyword, url, title, timestamp FROM yourls_url ORDER BY timestamp DESC LIMIT 30"xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"><row><fieldname="keyword">VV</field><fieldname="url">https://webdevbev.co.uk/blog/06-2021/perfect-is-the-enemy-of-good.html</field><fieldname="title"> Perfect is the enemy of good || Web Dev Bev</field><fieldname="timestamp">2021-09-26 17:38:32</field></row><row><fieldname="keyword">VU</field><fieldname="url">https://webdevlaw.uk/2021/01/30/why-generation-x-will-save-the-web/</field><fieldname="title">Why Generation X will save the web Hi, Im Heather Burns</field><fieldname="timestamp">2021-09-26 17:38:26</field></row><!-- ... etc. ... --></resultset>
We don’t see this, though. It’s piped directly into the second part of the command, which uses xsltproc to apply an XSLT to it. I was concerned that my XSLT
experience would be super rusty as I haven’t actually written any since working for my former employer SmartData back in around 2005! Back then, my coworker Alex and I spent many hours doing XML
backflips to implement a system that converted complex data outputs into PDF files via an XSL-FO intermediary.
I needn’t have worried, though. Firstly: it turns out I remember a lot more than I thought from that project a decade and a half ago! But secondly, this conversion from MySQL/MariaDB
XML output to RSS turned out to be pretty painless. Here’s the
template.xslt I ended up making:
<?xml version="1.0"?><xsl:stylesheetxmlns:xsl="http://www.w3.org/1999/XSL/Transform"version="1.0"><xsl:templatematch="resultset"><rssversion="2.0"xmlns:atom="http://www.w3.org/2005/Atom"><channel><title>Dan's Short Links</title><description>Links shortened by Dan using danq.link</description><link> [ MY RSS FEED URL ]</link><atom:linkhref=" [ MY RSS FEED URL ] "rel="self"type="application/rss+xml"/><lastBuildDate><xsl:value-ofselect="row/field[@name='pubdate']"/> UTC</lastBuildDate><pubDate><xsl:value-ofselect="row/field[@name='pubdate']"/> UTC</pubDate><ttl>1800</ttl><xsl:for-eachselect="row"><item><title><xsl:value-ofselect="field[@name='title']"/></title><link><xsl:value-ofselect="field[@name='url']"/></link><guid>https://danq.link/<xsl:value-ofselect="field[@name='keyword']"/></guid><pubDate><xsl:value-ofselect="field[@name='pubdate']"/> UTC</pubDate></item></xsl:for-each></channel></rss></xsl:template></xsl:stylesheet>
That uses the first (i.e. most-recent) shortlink’s timestamp as the feed’s pubDate, which makes sense: unless you’re going back and modifying links there’s no more-recent
changes than the creation date of the most-recent shortlink. Then it loops through the returned rows and creates an <item> for each; simple!
The final step in my command runs the output through xmllint to prettify it. That’s not strictly necessary, but it was useful while debugging and as the whole command takes
milliseconds to run once every quarter hour or so I’m not concerned about the overhead. Using these native binaries (plus a little configuration), chained together with pipes, had
already resulted in way faster performance (with less code) than if I’d implemented something using a scripting language, and the result is a reasonably elegant “scratch your
own itch”-type solution to the only outstanding barrier that was keeping me on S.2.
All that remained for me to do was set up a symlink so that the resulting output.rss.xml was accessible, over the web, to my RSS reader. I hope that next time I’m tempted to write a script to solve a problem like this I’ll remember that sometimes a chain of piped *nix
utilities can provide me a slicker, cleaner, and faster solution.
Update: Right as I finished writing this blog post I discovered that somebody had already solved this
problem using PHP code added to YOURLS; it’s just not packaged as a plugin so I didn’t see it earlier! Whether or not I
use this alternate approach or stick to what I’ve got, the process of implementing this YOURLS-database ➡ XML
➡ XSLT ➡ RSS chain was fun and
informative.
Plus many, many things that were new to me and that I’ve loved learning about these last few days.
It’s definitely not a competition; it’s a learning opportunity wrapped up in the weirdest bits of the field. Have an explore and feed your inner computer science geek.